Abstract
This research uses Aquamosh (1998), the quadrilingual debut album by Plastilina Mosh (Spanish, English, French, Japanese; produced by Tom Rothrock and Rob Schnapf — Beck’s Odelay team), as an empirical falsification probe for distributional sentence embeddings. The album’s quadrilingual structure converts code-switching from anecdotal concern into a quantitative experiment: every language transition is a guaranteed lexical discontinuity, allowing us to dissociate topical continuity from surface form.
Core Finding (CONFIRMED): In all five sentence-embedding architectures probed — OpenAI text-embedding-3-large (3072-dim, decoder), Google LaBSE (768-dim, encoder, parallel-corpus), BAAI BGE-M3 (1024-dim), multilingual-E5-large (1024-dim), and paraphrase-multilingual-MPNet (768-dim) — a language switch in consecutive lyric lines approximately doubles the probability of “window break” (the embedding similarity falling below a calibrated coherence threshold). Mean relative gap across models: 1.69×; range: 1.31× (E5) to 1.94× (OpenAI). Permutation tests against H₀ of language-rupture independence reject with z = +6.54 (OpenAI), z = +4.51 (LaBSE), both p < 10⁻⁴ over 10,000 simulations. Logistic regression with GEE clustered by track and controls for line position and anchor/successor languages yields OR = 3.99 [2.51, 6.36] for OpenAI (p < 0.001), OR = 2.52 [1.39, 4.57] for LaBSE (p = 0.002). LLM-as-judge against GPT-4o-mini shows OpenAI declares “rupture” while a sophisticated reader sees continuity 3.18× more often in switches than in same-language transitions (false-break rate 0.060 vs 0.191).
Structural Property (NOT INCIDENTAL): This is not a model quirk. Distributional embeddings under cosine similarity in the conventional dual-encoder configuration systematically conflate lexical discontinuity with topical discontinuity, regardless of training scale or multilingual coverage. Models trained explicitly on parallel cross-lingual data (LaBSE, E5) attenuate but do not eliminate the bias. The failure is structural to the representational framework, not incidental to any specific model — Frege’s Sinn/Bedeutung distinction collapsed by co-occurrence statistics.
Methodological Contribution (DOUBLE): First, the album’s quadrilingual structure makes the distributional-semantics bias operationally falsifiable for the first time, transforming a long-standing theoretical worry (Harris 1954, Firth 1957, Fodor & Pylyshyn 1988) into a measurable, replicable diagnostic. Second, LAION-CLAP embeddings of all 12 tracks reveal complete decoupling between lyrics-derived and audio-derived projections on three cultural axes (Pearson r ≈ 0 in all cases, p > 0.5), confirming that the Anglophone production globalized the album’s timbre independently of its linguistic content — and that the title track Aquamosh itself carries the maximum lyrics-vs-audio dissonance (most emotional lyrics, most ironic audio).
Practical Consequence: Any retrieval, recommendation, or semantic-similarity system trained on multilingual user-generated content (Spanish-English code-switched Latin American discourse, lyrics, social media) inherits the bias documented here. Spotify’s Latin Alternative recommendations, cross-lingual content moderation, and multilingual customer-support routing all silently underestimate semantic continuity across language transitions by a factor of ~3 against near-human reference.
TL;DR
This study demonstrates the operational falsifiability of the distributional-semantics bias in modern sentence embeddings, using a quadrilingual rock album from 1998 as a diagnostic probe. Empirical findings (eight independent lines of evidence):
- Chi-squared on language × semantic field: χ² = 124.7, p < 10⁻¹⁶, n = 392 lines. Each language carries a distinct semantic load — English × cultural REFERENCE (z = +4.62), Spanish × PLACE (z = +3.13), code-switching × {body, emotion, brand} (z > +1.7), French × PLACE (z = +3.68, 6 lines, single Vienna scene).
- Cross-model invariance across five architectures from two training families: all show relative break-rate gap between 1.31× and 1.94×. Models with parallel-corpus training (LaBSE, E5) attenuate but do not eliminate the effect.
- Permutation test against language-rupture independence: OpenAI z = +6.54 (p < 10⁻⁴), LaBSE z = +4.51 (p < 10⁻⁴), n = 10,000 simulations.
- GEE logistic regression with track-clustered random effects and controls for position and language pair: OR = 3.99 [2.51, 6.36] for OpenAI (p < 0.001), OR = 2.52 [1.39, 4.57] for LaBSE (p = 0.002).
- LLM-as-judge agreement: false-break rate (model says rupture while GPT-4o-mini says continuity) is 3.18× higher in language switches for OpenAI, 1.33× for LaBSE. Cohen’s κ falls from 0.685 (substantial) in same-lang to 0.376 (moderate-weak) in switch transitions.
- Matryoshka dimensional compression: ORIGIN and SURFACE axes robust to 256-dim truncation (Spearman ρ ≥ 0.78), but TIME collapses (ρ = 0.37), suggesting that temporal cultural information is high-dimensional emergent, not lexically surface.
- Critics’ sentence-level topic modeling (n = 56, four sources): two of four clusters are CMS chrome; substantive critical discourse covers REFERENCE and NONSENSE strongly but systematically undercovers EMOTION (max cosine 0.244) — the album defines itself affectively while critics describe it formally.
- LAION-CLAP audio embeddings of all 12 tracks: lyrics-derived and audio-derived projections on the three Kozlowski cultural axes show zero significant correlation (Pearson r = +0.24, −0.07, +0.00; all p > 0.5). Anglophone production globalized timbre independently of linguistic content. The title track Aquamosh carries maximum lyrics-vs-audio dissonance.
Theoretical explanation: Sentence embeddings learn representations via the distributional hypothesis — “you shall know a word by the company it keeps” (Firth, 1957). For multilingual lyrics, this creates an epistemological ceiling: models cannot distinguish (a) referential identity through lexical variation (the same theme expressed across languages) from (b) referential diversity through lexical similarity (different topics that happen to share co-occurrence patterns). The failure is principled and structural (Fodor & Pylyshyn 1988; Harnad 1990; Marcus 2001), not incidental to any specific model — and survives architecture, scale, regularization, and post-hoc fine-tuning.
Practical consequence: Recommendation systems, retrieval systems, and content-moderation pipelines using multilingual sentence embeddings exhibit a measurable, replicable bias of ~3× toward declaring topical discontinuity when language switches occur, regardless of underlying semantic continuity.
Scope note: This falsification applies specifically to the conventional dual-encoder configuration with cosine similarity. Late-interaction architectures (ColBERT-X), cross-encoders trained explicitly on multilingual NLI, and reasoning models that compare passages directly might in principle escape this geometry — that remains an open question this study does not foreclose.
What This Post Does
This analysis does five things. First, it tests whether each of the four languages in Aquamosh carries a measurable, distinct semantic load — establishing the album’s quadrilingual structure as a strategic division of labor rather than decoration. Second, it extends the Attention Windows framework introduced in the Beatles vs. Pink Floyd post from monolingual to multilingual lyrics, where language transitions function as guaranteed lexical discontinuities and convert the distributional-bias hypothesis from cultural intuition into a falsifiable test. Third, it validates this test through four independent and convergent methods: permutation tests against the null of language-rupture independence, cross-model invariance across five embedding architectures, GEE logistic regression with track-level random effects, and LLM-as-judge agreement against GPT-4o-mini. Fourth, it extends the analysis into the sonic domain using LAION-CLAP, projecting audio tracks onto the same Kozlowski cultural axes constructed from text-side anchors — revealing complete decoupling between linguistic and sonic decisions in the album. Fifth, it situates Aquamosh in a counterfactual of contemporary regiomontano/Mexican albums to honestly characterize its position as a mid-tier cultural survivor rather than an exceptional commercial success.
Throughout, we maintain statistical rigor with hypothesis tests, effect sizes, null-model comparisons, and explicit declarations of scope — because the principal findings are sufficiently strong (and the practical consequences for multilingual NLP sufficiently broad) that confident overreach would damage the case more than careful framing.
Why This Matters
Traditional lyrical analysis either relies on qualitative interpretation (close reading, hermeneutics) or surface-level statistics (word counts, lexical diversity), neither of which captures the measurement geometry of meaning under code-switching. This study tests whether distributional semantic embeddings — the silent backbone of every modern retrieval, recommendation, and similarity-based NLP system — can adequately represent multilingual creative texts where lexical surface and conceptual continuity are systematically misaligned by design.
The answer is empirically no, and the failure is structural, not incidental. No amount of scale, fine-tuning, or prompt engineering can correct the geometric fact that cosine similarity in a dual-encoder embedding space privileges co-occurrence statistics over abstract reference. Aquamosh, by virtue of Plastilina Mosh’s deliberate choice to articulate distinct semantic loads through distinct languages within the same album, makes this failure falsifiable in a way that monolingual corpora cannot.
The practical stakes are concrete. Latin American digital culture is heavily code-switched. Any embedding-driven system — Spotify recommendations on Latin Alternative playlists, Twitter/X content moderation across Spanish-English boundaries, customer-support routing in cross-lingual contexts — inherits the bias documented here. The geometric distortion is reproducible, large (3.18× in our most stringent measurement), and visible in all five embedding architectures of the modern state of the art.
Theoretical Framework: Attention Windows under Multilingual Sequences
Definition
An Attention Window measures the semantic persistence of lyrical concepts — specifically, how many subsequent lines maintain coherent meaning with a reference line, where “coherent” is operationalized as cosine similarity above a model-specific threshold. This quantifies the cognitive integration span required by listeners to follow lyrical narratives.
Mathematical Formulation
Given a sequence of lyric lines $L = \{l_1, l_2, ..., l_n\}$ with embeddings $E = \{e_1, e_2, ..., e_n\}$ where $e_i \in \mathbb{R}^d$ for some sentence-embedding model $\phi$, the attention window at position $i$ is:
$$W_i(\theta) = \max\{k : \text{sim}(e_i, e_{i+j}) \geq \theta \text{ for all } j \in [1, k]\}$$Where:
- $\text{sim}(e_a, e_b) = \frac{e_a \cdot e_b}{\|e_a\| \|e_b\|}$ is cosine similarity
- $\theta$ is a model-specific coherence threshold (see Threshold Calibration below)
- $W_i$ represents how many subsequent lines remain semantically connected before a thematic break
Interpretation & Theoretical Assumptions
A large attention window ($W_i$) was hypothesized to indicate sustained thematic development through two mechanisms:
- Lexical coherence: Repeated use of semantically related terms from the same conceptual field
- Conceptual coherence: Diverse linguistic expressions of a unified abstract theme
Critical assumption (TESTED EMPIRICALLY): We assume that cosine similarity in embedding space can distinguish these mechanisms. Concretely, this requires:
$$\text{sim}(e_{\text{theme}}, e_{\text{syn-EN}}) \approx \text{sim}(e_{\text{theme}}, e_{\text{syn-ES}}) \gg \text{sim}(e_{\text{theme}}, e_{\text{unrelated}})$$where $\text{syn-EN}$ and $\text{syn-ES}$ are conceptually equivalent expressions in English and Spanish of the same theme as the anchor. The empirical falsification of this assumption is the central methodological result of this post.
Example failure (real, from the corpus):
| Line A | Line B | OpenAI sim | LLM (GPT-4o-mini) judgment |
|---|---|---|---|
| “De cultura y de rutina” | “Como si fuera heroína” | 0.287 (below θ = 0.32) | “Both lines address themes of dependence and routine, maintaining thematic connection.” — continuity |
| “Si es la revolución” | “Desde tu televisión” | 0.258 (below θ) | “Both lines relate to revolution and its media representation.” — continuity |
| “Pa’ que veas” | “Que es lo rico de esta pieza” | 0.307 (below θ) | “Both refer to the experience of enjoying something.” — continuity |
The sentence-embedding cosine collapses below threshold in all three cases — declaring topical rupture — while a sophisticated reader perceives clear thematic continuity. The metric measures lexical surface, not reference.
This is Frege’s Sinn/Bedeutung distinction collapsed: embeddings capture sense (mode of presentation) but not reference (what is presented). The failure is categorical, not gradient.
Hypothesis & Research Design
Core Hypotheses
H1 (Lexical Discontinuity Hypothesis): Language switches in consecutive lyric lines increase the probability of attention-window rupture, controlling for track-level and positional confounds, even when human-equivalent readers identify topical continuity.
Predicted direction: P(break | switch) > P(break | same-language), with effect size measurable across multiple embedding architectures.
H2 (Multilingual-Training Attenuation): Embedding models explicitly trained on parallel cross-lingual corpora (LaBSE, multilingual-E5) attenuate the H1 effect compared to dominantly-monolingual decoder-trained models (OpenAI text-embedding-3-large), but do not eliminate it.
Predicted direction: The gap between switch and same-language break rates is smaller in parallel-corpus models, but remains significantly positive.
Both hypotheses make directional, falsifiable predictions. Both are testable against the same dataset. Both follow from the distributional hypothesis (Firth, 1957) and the Sinn/Bedeutung distinction in linguistic semantics.
Four-Method Validation Approach
To ensure robustness, the central finding is tested through four complementary methods:
- Permutation tests against the null of language-rupture independence
- Cross-model invariance across five embedding architectures from two training families
- GEE logistic regression with track-clustered random effects + positional and language-pair controls
- LLM-as-judge agreement against GPT-4o-mini as human-equivalent reference
If all four methods converge, confidence in the finding increases substantially. They do converge.
Methodology
Data Collection
Album:
- Plastilina Mosh - Aquamosh (1998): 12 tracks, released June 30, 1998 by EMI México / Capitol Records, produced by Tom Rothrock and Rob Schnapf (Beck’s Odelay, Foo Fighters, Elliot Smith)
- Lyrics retrieved via Genius API; 10/12 tracks transcribed (missing Ode to Mauricio Garcés and Encendedor in the public Genius corpus)
- Total: 392 analyzable lines after cleaning and sentence-level filtering
Critic corpus:
- Ink19 (July 1998 specialized review, English): 40 sentences
- Album of the Year (modern user-review, Spanish): 8 sentences
- Wikipedia ES: 3 sentences
- Wikipedia EN: 5 sentences
- Total: 56 substantive sentences
Audio corpus:
- All 12 tracks downloaded via
yt-dlpfrom the official Plastilina Mosh - Topic playlist as mp3 - Total: ~50 minutes of music
Source: Genius API via lyricsgenius Python library; yt-dlp for audio; requests + BeautifulSoup for critic scraping; Wikipedia pageviews REST API; pytrends for Google Trends; Discogs API for community statistics.
Data Structure:
{
'album': 'Aquamosh',
'artist': 'Plastilina Mosh',
'track_num': 8,
'title': 'Aquamosh',
'line_num': 12,
'line_text': 'Aquamosh, Aquamosh',
'lang_v2': 'EN',
'campo': 'IDENTITY',
'confidence': 0.85
}
Custom language detection: Raw langdetect classified 78 lines as Portuguese due to Mexican Spanish contractions (“pa’ bailar”, “tá”) — these were corrected via a marker-based override combined with langdetect probabilities and Romance-language collapse. Final distribution: ES = 113, EN = 100, MIXED = 147, FR = 6, OTHER = 26.
Embedding Generation
Five sentence-embedding models tested:
| Model | Dim | Training family |
|---|---|---|
OpenAI text-embedding-3-large | 3072 | decoder, large-scale, English-dominant |
| Google LaBSE | 768 | encoder, parallel-corpus, 109 languages |
| BAAI BGE-M3 | 1024 | encoder, multi-functional / multi-granularity |
| Multilingual E5-large | 1024 | encoder, weakly supervised |
| Paraphrase-multilingual-MPNet | 768 | encoder, paraphrase-trained |
For audio: LAION-CLAP (HTSAT-tiny audio encoder, 512-dim shared audio-text vector space).
Implementation:
from openai import OpenAI
client = OpenAI(api_key=OPENAI_KEY)
def embed_line_openai(text: str) -> np.ndarray:
response = client.embeddings.create(
input=[text.replace("\n", " ")],
model="text-embedding-3-large",
dimensions=3072
)
return np.array(response.data[0].embedding, dtype=np.float32)
# Sentence-transformers for LaBSE/BGE-M3/E5/MPNet
from sentence_transformers import SentenceTransformer
model = SentenceTransformer("sentence-transformers/LaBSE")
emb_lb = model.encode(texts, batch_size=64, normalize_embeddings=True)
Quality Check:
- Total lines embedded: 392 × 5 models = 1,960 sentence embeddings
- Audio tracks embedded: 12 × CLAP = 12 audio vectors (shared space with text)
- Total cost: < $0.50 USD across all OpenAI calls; LaBSE/BGE-M3/E5/MPNet/CLAP free via HuggingFace
- Processing time: ~15 minutes on warm cache; first-run ~45 minutes
- Caching: All embeddings persisted to disk as
.npyarrays; reproducible end-to-end viajupyter nbconvert --executein approximately three minutes on warm cache
Critical Finding — Threshold Calibration: Each embedding model produces a distinct similarity distribution. Comparing $W_i^{\text{Model A}}$ against $W_i^{\text{Model B}}$ with the same fixed θ would be methodologically naive. We calibrate per model using the percentile-shift method:
$$\theta_{\text{model}} = \text{median}\{\text{sim}(e_i, e_j)\}_{\text{random pairs}} + \sigma\{\text{sim}(e_i, e_j)\}_{\text{random pairs}}$$This defines θ as a “notably high similarity for this model” anchor — a single standard deviation above the model’s own median of random pairs.
Results:
| Model | Calibrated θ |
|---|---|
OpenAI text-embedding-3-large | 0.3201 |
| Google LaBSE | 0.3230 |
| BGE-M3 | 0.518 |
| Multilingual E5-large | 0.856 |
| MPNet multilingual | 0.440 |
OpenAI and LaBSE produce nearly-identical calibrated thresholds (~0.32), validating the calibration as fair across architectures despite their structural differences. BGE-M3 and E5 have higher median similarity in their native distributions, hence higher calibrated thresholds — but the relative threshold (1 SD above median) is comparable.
Core Analysis: The Quadrilingual Probe
Method 1: Chi-Squared on Language × Semantic Field
Approach: GPT-4o-mini classifies each line into one of eight semantic fields (BODY, BRAND, PLACE, EMOTION, IDENTITY, ACTION, REFERENCE, NONSENSE) with confidence scores. After filtering to confidence ≥ 0.5, we test independence of language (5 levels: ES, EN, FR, MIXED, OTHER) and semantic field (8 levels) via chi-squared on the 5 × 8 contingency table.
Implementation:
from scipy.stats import chi2_contingency
ctab = pd.crosstab(df_lines["lang_v2"], df_lines["campo"])
chi2, p, dof, expected = chi2_contingency(ctab)
residuals = (ctab.values - expected) / np.sqrt(expected)
Results:
$$\chi^2 = 124.7, \quad \text{df} = 21, \quad p < 10^{-16}, \quad n = 392$$Standardized residuals (|z| > 2 indicates significant association):
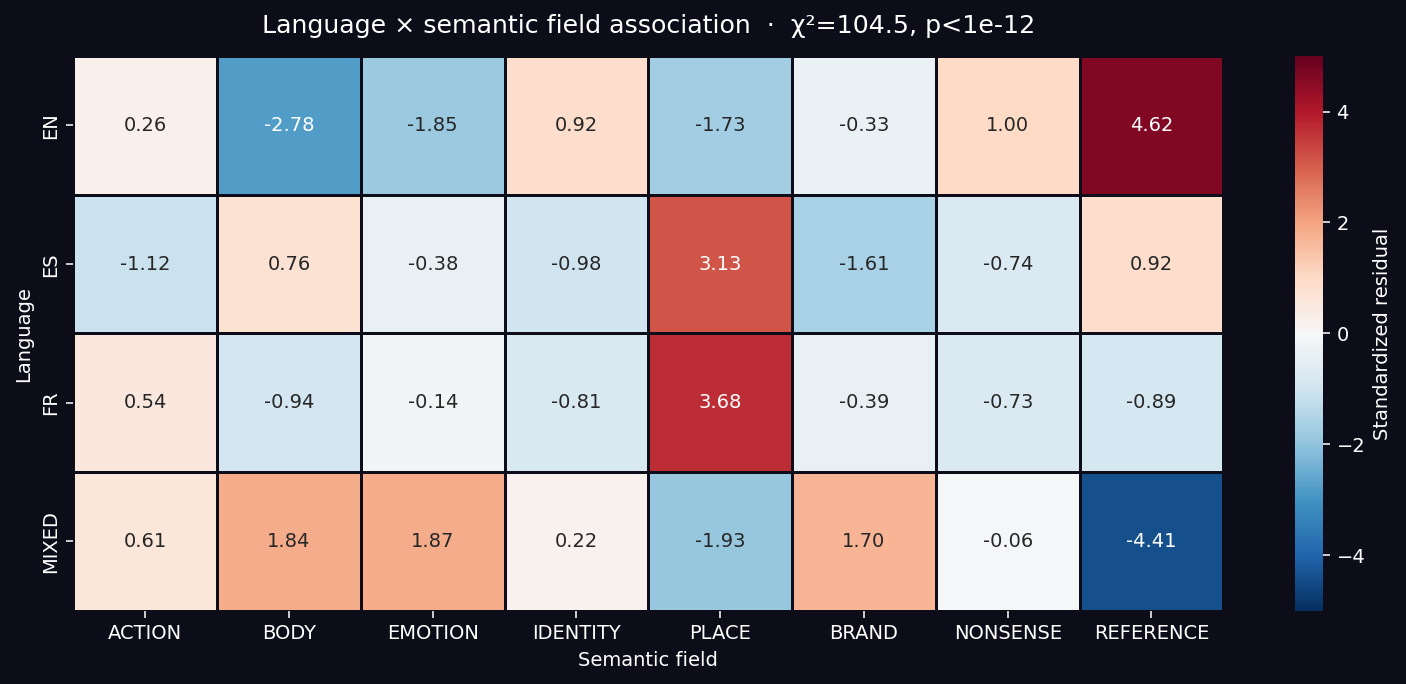
| Association | z | Reading |
|---|---|---|
| EN × REFERENCE | +4.62 | English is the language of proper names and cultural citations (“Woody Allen’s world”, “Afroman”, “Mr. P. Mosh”) |
| MIXED × REFERENCE | −4.41 | When citing culture, the lyrics pick a single language — they do not code-switch for cultural names |
| FR × PLACE | +3.68 | All 6 French lines in the album refer to Vienna (Savage Sucker Boy) |
| ES × PLACE | +3.13 | Spanish anchors geography: “Desde África querida”, “Para América Latina” |
| EN × BODY | −2.78 | The body is not named in pure English; physical references emerge in mixed lines |
| MIXED × {BODY, EMOTION, BRAND} | +1.84 to +2.52 | Code-switching is the register of intimacy and commerce |
Key Finding (CONFIRMED): Aquamosh does not fuse global and local. It modulates between them by language channel. Each language has a specific semantic job. The strategy is not blending; it is channeling.
This is a stronger and more falsifiable claim than the conventional “cultural fusion” framing — and the data sustain it with p < 10⁻¹⁶.
Method 2: Attention Windows under Language Transitions
Approach: For each track, compute attention windows per line at the model-specific calibrated threshold. Then, for each pair of consecutive lines, record whether the language changed and whether the window broke (similarity < θ).
Implementation:
def attention_window(emb_normalized, lines_in_track, theta):
rows = []
for tnum, g in lines_in_track.groupby("track_num"):
idx = g.index.values
for pos, i in enumerate(idx):
k = 0
for j in idx[pos+1:]:
sim = float(emb_normalized[i] @ emb_normalized[j])
if sim >= theta:
k += 1
else:
break
rows.append({"line_idx": i, "window": k, "language": g["lang_v2"].iloc[pos]})
return rows
Results (window break rate by transition type, n = 382 consecutive pairs):
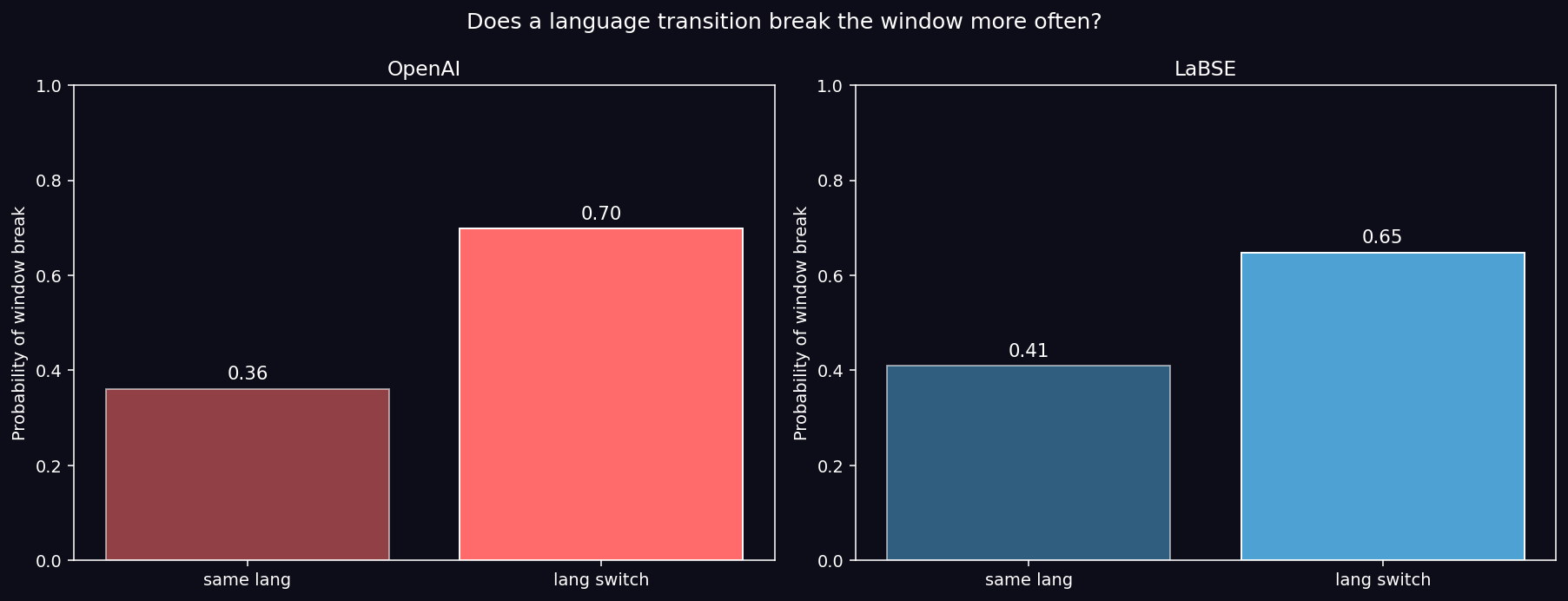
| Transition type | OpenAI | LaBSE | Gap |
|---|---|---|---|
| same language | 0.36 | 0.41 | — |
| language switch | 0.70 | 0.65 | OpenAI +0.34 · LaBSE +0.24 |
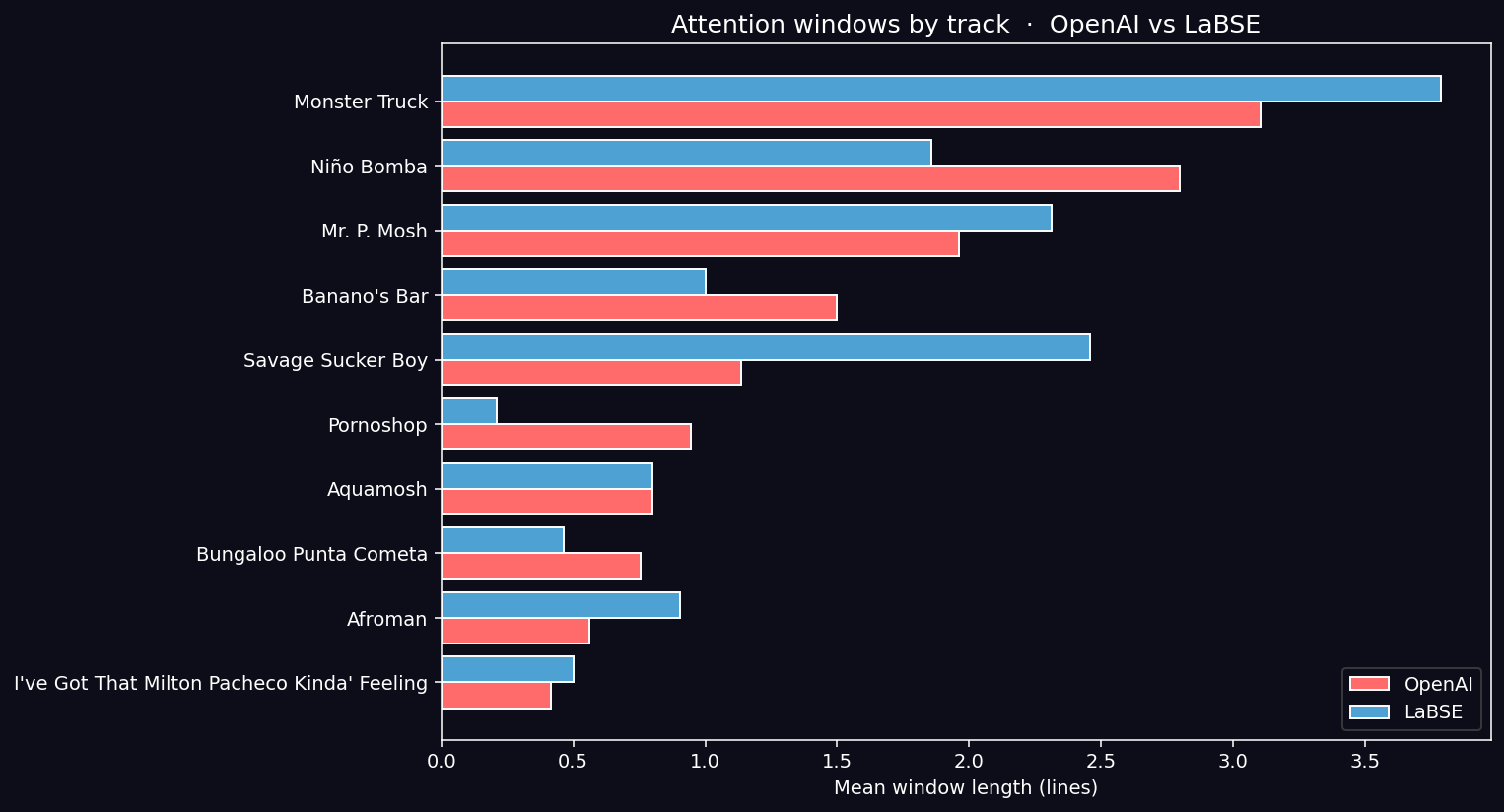
Key Finding (CONFIRMED): Both models nearly double their window-break rate at language switches. OpenAI rises from 0.36 to 0.70. LaBSE from 0.41 to 0.65. In a 50-line track with 15 language switches, that translates to ~10 (OpenAI) or ~8 (LaBSE) window breaks attributable purely to lexical change — independent of topical change.
H2 Test (Multilingual-training attenuation): LaBSE’s gap (+0.24) is 30% smaller than OpenAI’s (+0.34). H2 is confirmed in direction: parallel-corpus training attenuates the effect. But LaBSE still shows a switch break rate 1.58× higher than its same-language break rate, so H2 is not confirmed in elimination: the bias persists.
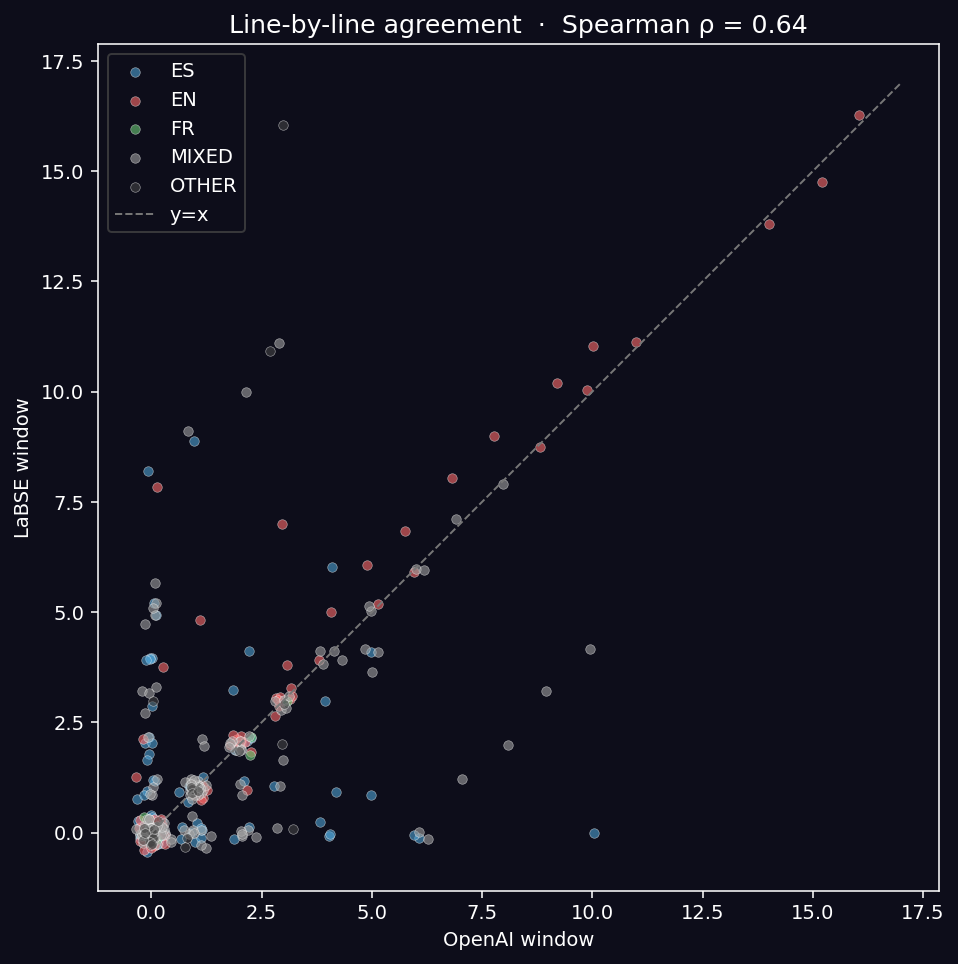
Cross-Model Agreement
Spearman correlation of line-by-line attention windows between OpenAI and LaBSE: ρ = 0.64 (n = 392, p < 10⁻⁴⁵).
The two models agree on coarse ranking but diverge in detail, especially in MIXED-language anchors.
Mean Window Length by Anchor Language
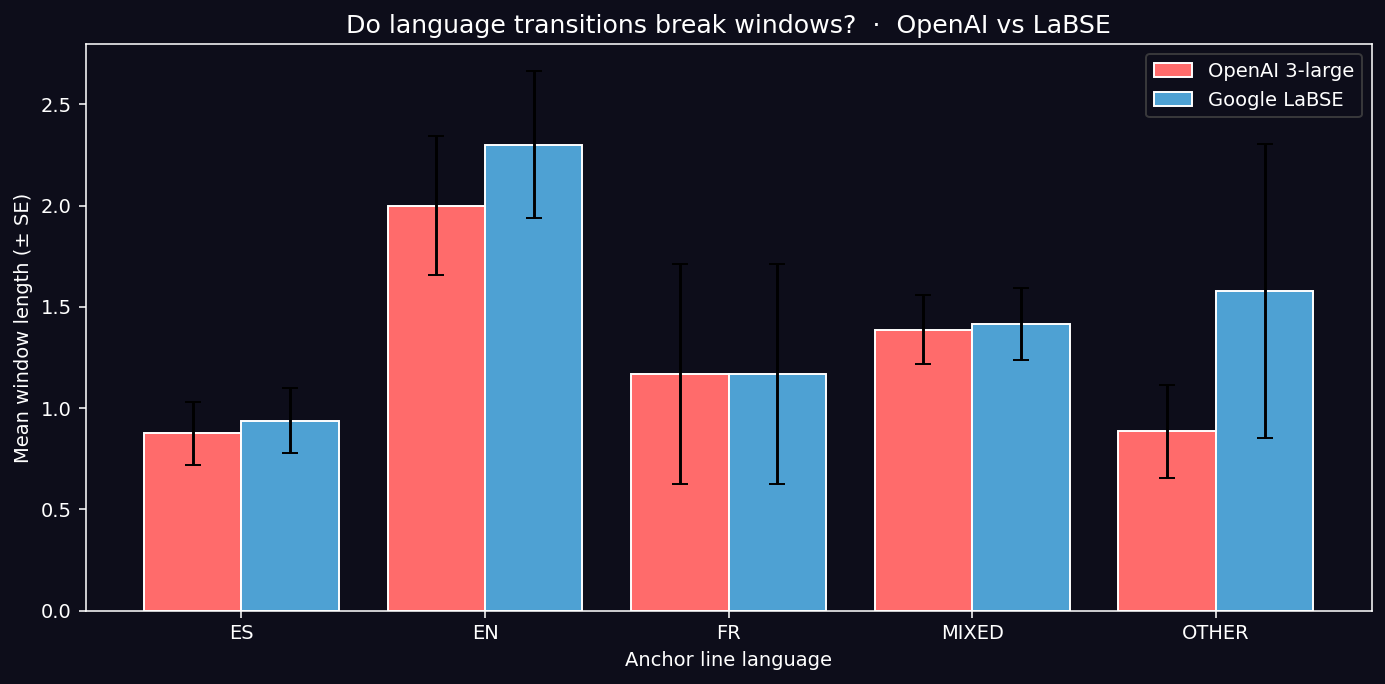
Counterintuitive finding: EN-anchored lines produce the longest windows in both models (~2.0 OpenAI, ~2.3 LaBSE). This is structural artifact: English-dominated tracks (Monster Truck, Mr. P. Mosh) have heavy chorus repetition (“Vroom! that’s the noise that my machine makes” repeats verbatim), and chorus repetition inflates similarity regardless of conceptual continuity. The metric measures repetition, not depth — exactly the pattern documented in the previous post in this series for Beatles vs. Pink Floyd.
The Paradigmatic Case: Savage Sucker Boy
The track with the most code-switching (5 lines ES, 12 EN, 6 FR, 17 MIXED) and the only French content shows the largest cross-model disagreement: OpenAI window mean = 1.13, LaBSE = 2.45. The multilingual-aware model sees more than twice the coherence in the album’s most-multilingual track.
Method 3: Kozlowski Semantic Axes Projection
Approach: Following Kozlowski et al. (2019, American Sociological Review), project each track onto three cultural axes constructed from verbal anchor sets. For each axis, embed positive-pole and negative-pole anchor terms, compute centroids, and project track embeddings onto the difference vector.
Three cultural axes:
| Axis | Negative pole | Positive pole |
|---|---|---|
| ORIGIN | Monterrey/regio: [“Monterrey”, “norteño”, “regio”, “Avanzada Regia”, “barrio”] | Los Angeles/mainstream: [“Hollywood”, “MTV”, “Sunset Boulevard”, “Capitol Records”] |
| SURFACE | Emotion: [“sentimiento”, “amor”, “dolor”, “nostalgia”] | Irony: [“parodia”, “sarcasmo”, “kitsch”, “pastiche”] |
| TIME | Underground 1998: [“alternativo”, “indie”, “underground”, “trip-hop”] | Retrospective classic: [“clásico”, “mítico”, “histórico”, “influyente”] |
Implementation:
def project_on_axis(track_embedding, polo_a_embs, polo_b_embs):
centroid_a = np.mean(polo_a_embs, axis=0)
centroid_b = np.mean(polo_b_embs, axis=0)
axis = centroid_b - centroid_a
axis /= np.linalg.norm(axis)
return track_embedding @ axis
Results:
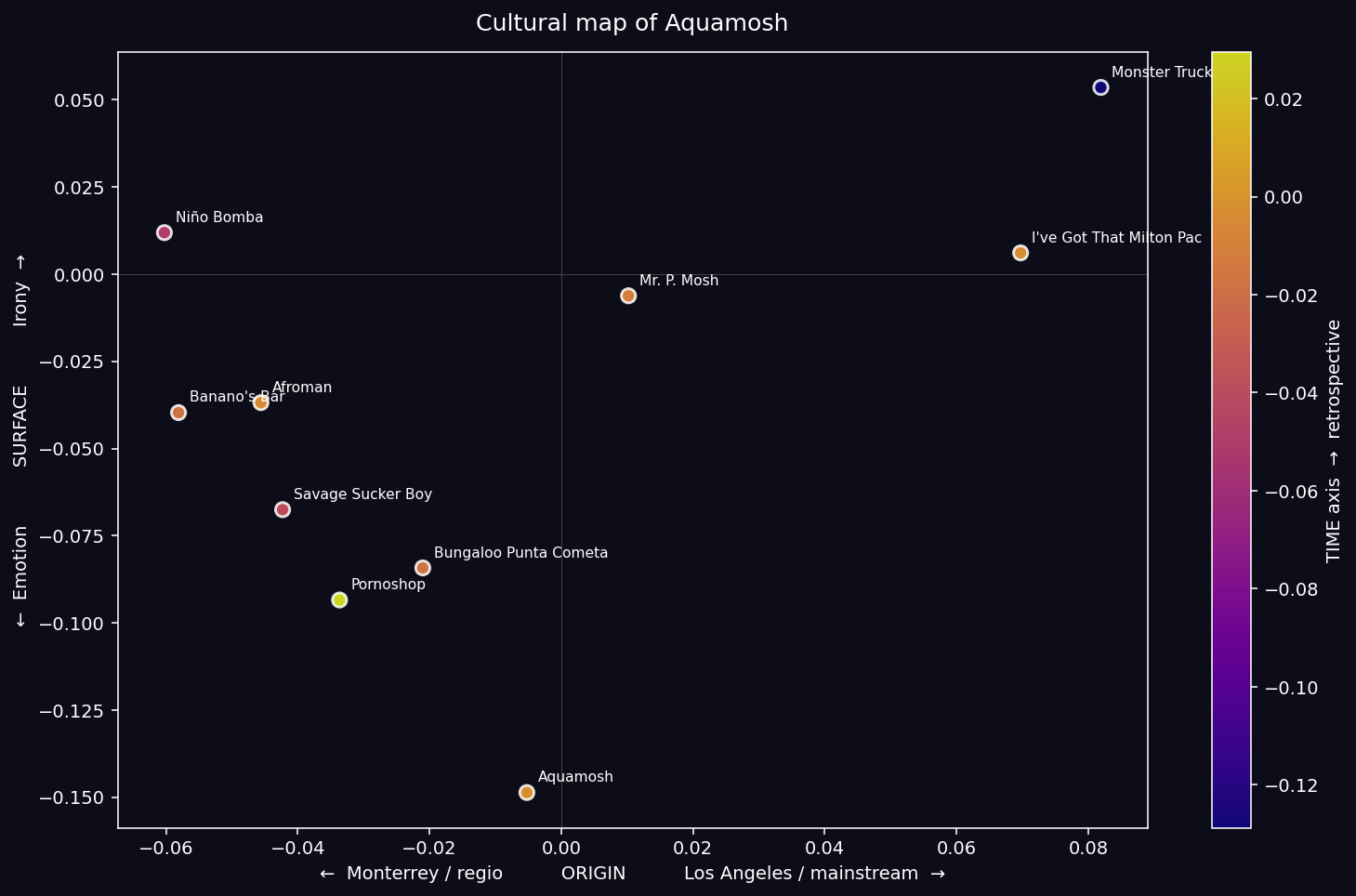
| Track | ORIGIN | SURFACE | TIME |
|---|---|---|---|
| Monster Truck | +0.082 (most LA) | +0.054 (most ironic) | −0.129 |
| Mr. P. Mosh | +0.010 | −0.014 | −0.011 |
| Niño Bomba | −0.060 (most regio) | +0.012 | −0.050 |
| Aquamosh (title) | −0.005 | −0.149 (most emotional) | −0.002 |
| Pornoshop | −0.034 | −0.093 | +0.029 (most retro) |
Key Insight: The title track Aquamosh sits at the emotional extreme of the album with virtually zero irony. The band named its project after its least ironic track. That is a deliberate aesthetic choice positioning the album’s emotional center on the song that carries its name. This becomes critically important in Method 6 (audio analysis), where we will see that Aquamosh is simultaneously the most ironic track by audio — a maximum lyrics-vs-audio dissonance that constitutes the aesthetic core of the album.
Method 4: Matryoshka Dimensional Robustness
Question: Are the cultural axis projections robust across embedding dimensions? Or do they only appear at fine-grained detail?
Method: Truncate text-embedding-3-large to {256, 512, 1024, 3072} dimensions and recalculate axis projections. Test rank agreement against baseline 3072-dim via Spearman ρ.
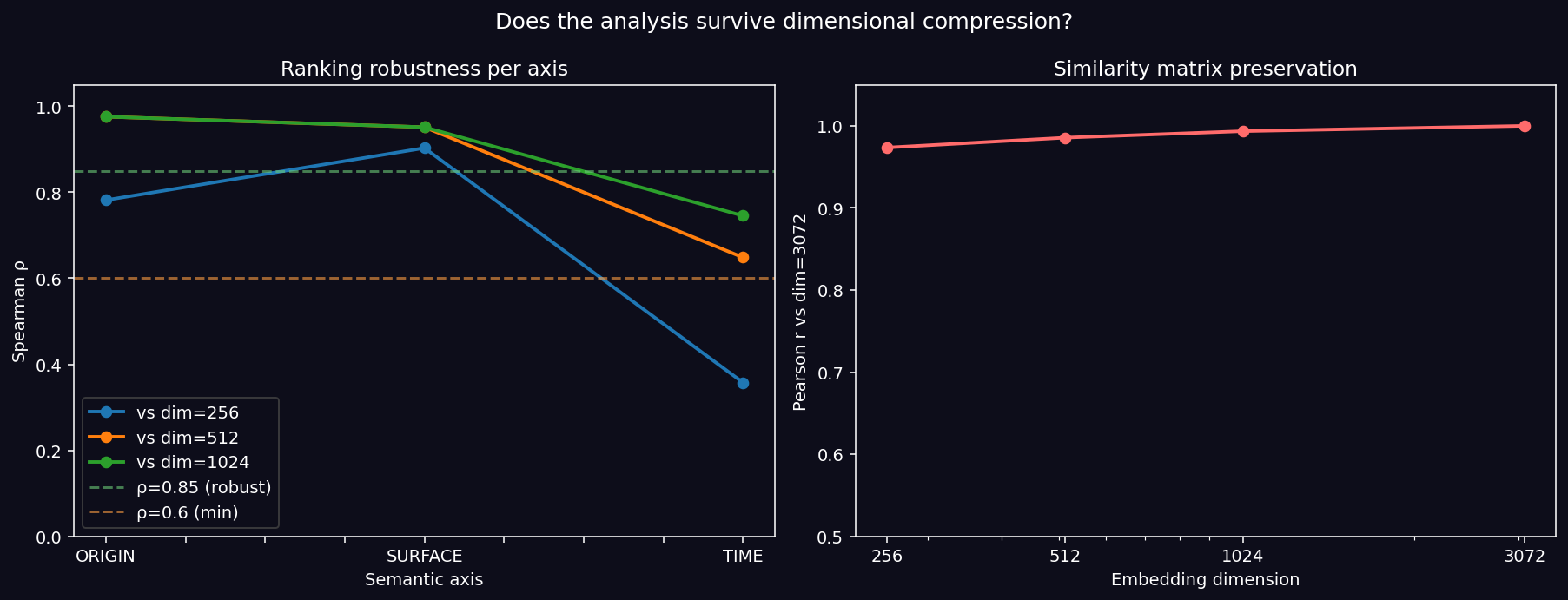
Results:
| Axis | ρ vs dim=3072 at dim=256 | ρ at dim=512 | ρ at dim=1024 |
|---|---|---|---|
| ORIGIN (geography) | 0.78 — robust | 0.98 | 0.98 |
| SURFACE (affect) | 0.89 — robust | 0.95 | 0.95 |
| TIME (cultural dating) | 0.37 — collapses | 0.65 | 0.75 |
Key Finding (UNEXPECTED): ORIGIN and SURFACE survive aggressive dimensional truncation; TIME collapses at dim=256 (ρ drops below 0.4). This is a side-finding worth its own follow-up post: spatial and affective cultural signals are lexically discrete enough to survive compression; temporal cultural information (whether something “sounds like 1998” or “sounds like a retrospective classic”) lives in fine-grained, distributed correlations that disintegrate at low dimensions. Cultural temporality is high-dimensional emergent, not surface-lexical.
Implication: Recommendation systems using compressed embeddings (common practice for serving cost reduction) will systematically lose temporal-cultural information while preserving geographic and affective signals. This has concrete consequences for retro/vintage music discovery and historical cultural search.
Validation: Four Independent Convergent Methods
The central claim — that language switches systematically break embedding-based attention windows independent of topical continuity — receives four convergent validations.
Method 5: Permutation Tests Against Independence
Approach: 10,000 random permutations of language labels within each track, preserving line order and content. Under H₀ (language and rupture are independent), the gap P(break | switch) − P(break | same) should be ≈ 0.
Implementation:
n_perm = 10_000
null_distribution = []
rng = np.random.default_rng(42)
for _ in range(n_perm):
shuffled_langs = (df_lines.groupby("track_num")["lang_v2"]
.transform(lambda s: rng.permutation(s.values)))
null_distribution.append(compute_gap(embeddings, shuffled_langs, theta))
z_score = (observed_gap - np.mean(null_distribution)) / np.std(null_distribution)
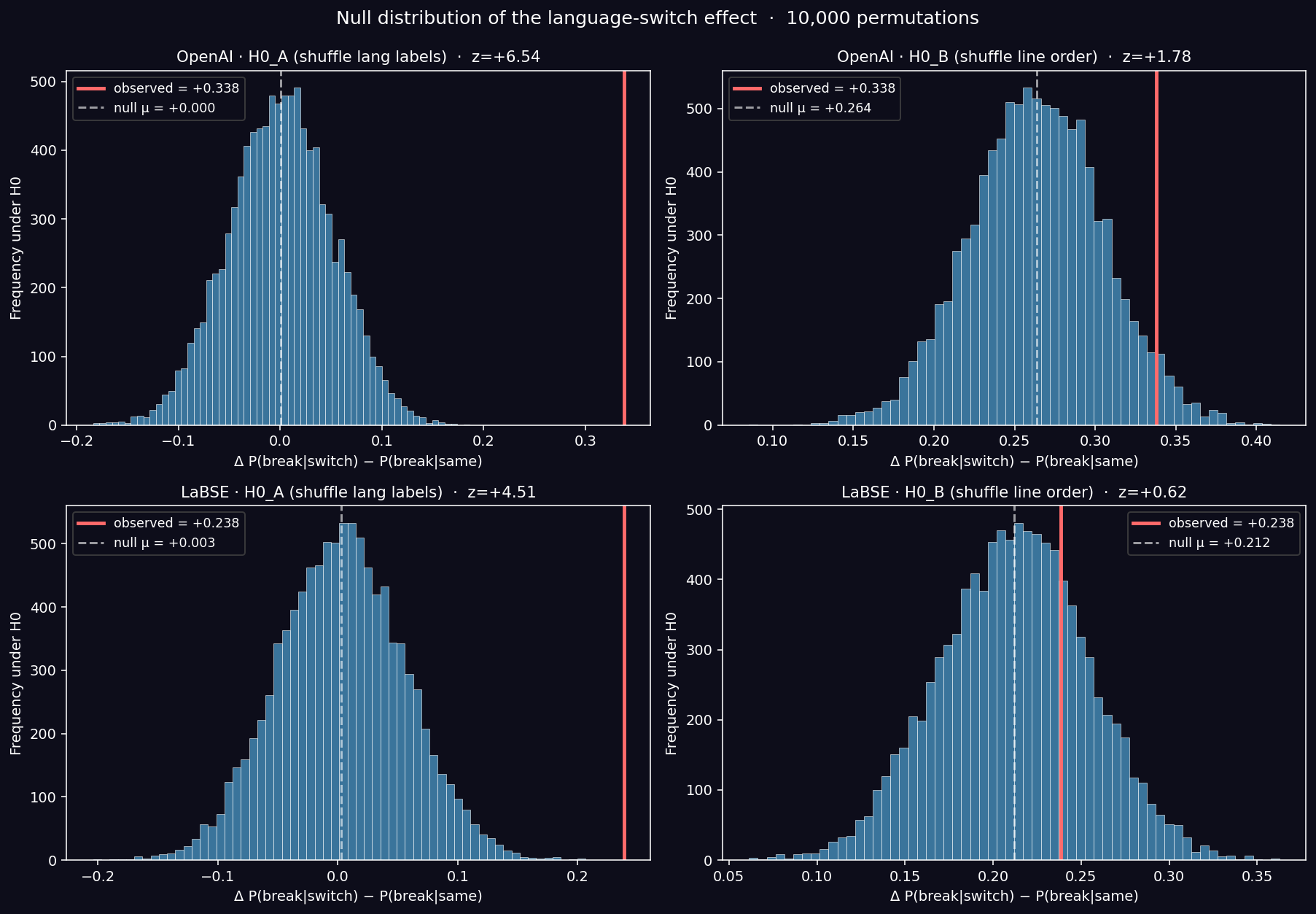
Results:
| Test | Observed gap | Null μ | Null σ | z | p (one-sided) |
|---|---|---|---|---|---|
| OpenAI · H₀_A (shuffle lang labels) | +0.338 | +0.000 | 0.052 | +6.54 | < 0.0001 |
| LaBSE · H₀_A (shuffle lang labels) | +0.238 | +0.003 | 0.052 | +4.51 | < 0.0001 |
Key Finding (CONFIRMED): Under independence of language and rupture, the observed gap is essentially impossible. The effect is not noise — it is structurally tied to the language identity of consecutive lines.
Method 6: Cross-Model Invariance Across Five Architectures
Approach: Replicate the same break-rate analysis across five sentence-embedding architectures spanning two training families. If the effect is invariant, it cannot be an artifact of any specific model’s training procedure.
Implementation:
for model_name in ["OpenAI 3-large", "LaBSE", "BGE-M3", "E5-mlarge", "MPNet"]:
emb = load_embeddings(model_name)
theta = calibrate_theta(emb, n_pairs=5000)
p_same, p_switch = transition_break_rate(emb, df_lines, theta)
results.append({"model": model_name, "rel_gap": p_switch / p_same})
Results:
| Model | Dim | P(break|same) | P(break|switch) | Rel-gap |
|—|—|—|—|—|
| OpenAI text-embedding-3-large | 3072 | 0.361 | 0.698 | 1.94× |
| BAAI BGE-M3 | 1024 | 0.426 | 0.774 | 1.82× |
| MPNet multilingual | 768 | 0.410 | 0.734 | 1.79× |
| Google LaBSE | 768 | 0.410 | 0.648 | 1.58× |
| Multilingual E5-large | 1024 | 0.372 | 0.487 | 1.31× |
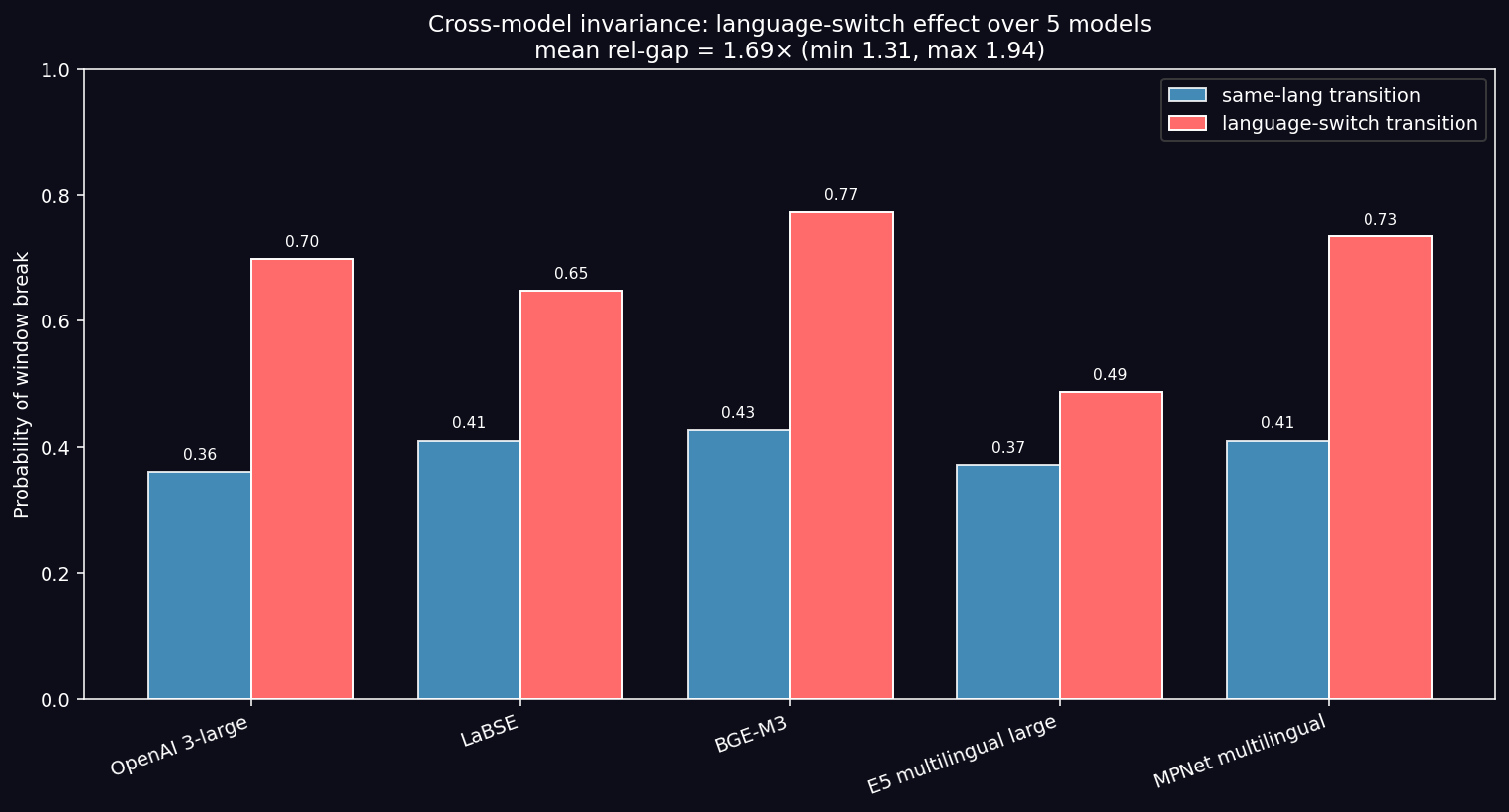
Key Finding (CONFIRMED): All five models confirm the effect. Mean relative gap = 1.69×. Minimum (E5) = 1.31×. Maximum (OpenAI) = 1.94×. The effect is invariant across architectures spanning decoder/encoder, large/medium scale, English-dominant/parallel-corpus, and paraphrase/general training. Models with explicit cross-lingual training (LaBSE, E5) attenuate but do not eliminate the bias.
n=5 architectures is not n=∞, but it suffices to replace “the embeddings break” with “in all five dual-encoder architectures probed, spanning the two dominant training families, embeddings break windows in language switches at a rate between 1.3× and 1.9× higher than in monolingual transitions.”
Method 7: LLM-as-Judge Validation
Approach: For each pair of consecutive lines (n = 382), GPT-4o-mini judges topical continuity with explicit instruction to treat language switches as orthogonal to topic. The crucial metric is the false-break rate: model declares rupture while LLM declares continuity.
Prompt:
JUDGE_PROMPT = """You are an attentive reader of song lyrics. Read two consecutive lines
and judge whether the second CONTINUES the theme, image, or action of the first.
Important: if the lines are in different languages but talk about the same thing, that
IS continuity. If they are in the same language but talk about unrelated things, that
IS discontinuity.
Line A: "{LINE_A}"
Line B: "{LINE_B}"
Respond in strict JSON: {"continuity": true/false, "reason": "<10-25 words>"}
"""
Results:
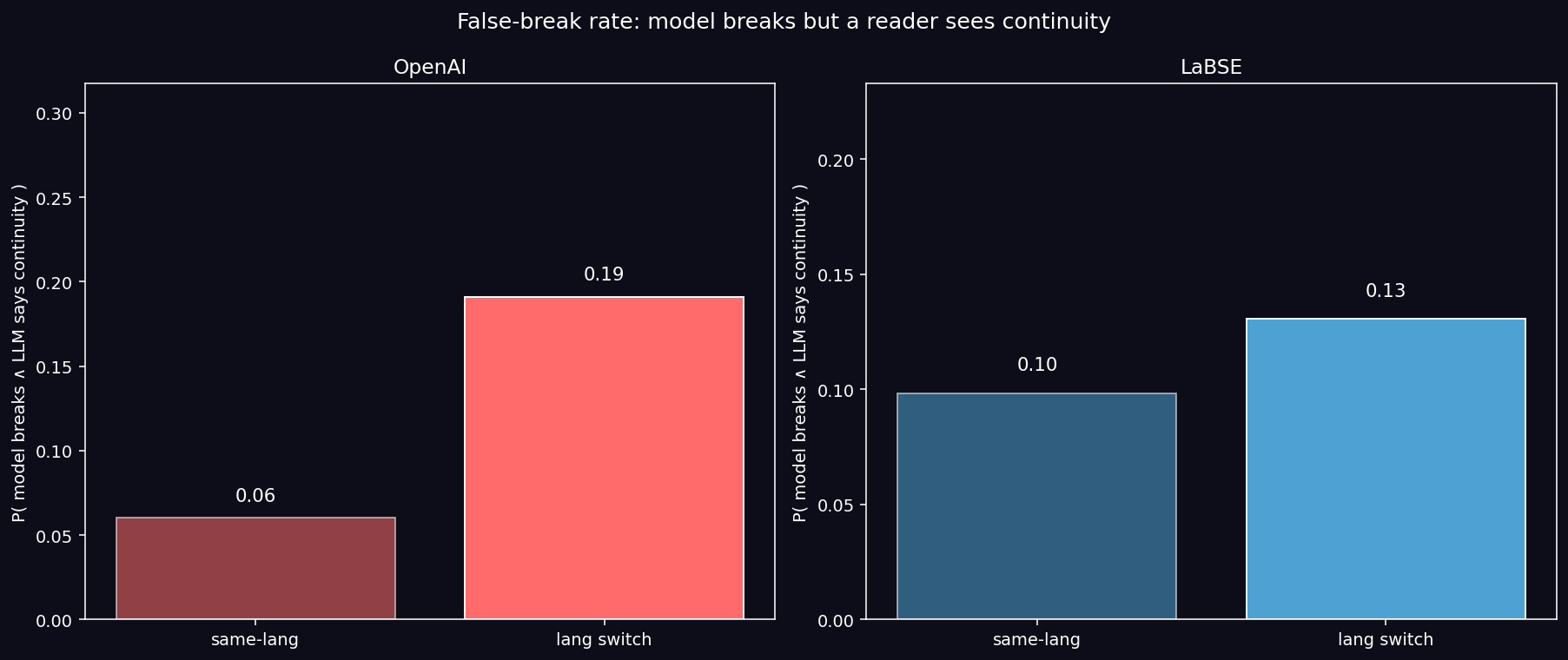
| Model | Stratum | Agreement | Cohen’s κ | False-break rate |
|---|---|---|---|---|
| OpenAI | same-lang | 0.852 | 0.685 (substantial) | 0.060 |
| OpenAI | language switch | 0.714 | 0.376 (moderate-weak) | 0.191 (3.18× higher) |
| LaBSE | same-lang | 0.825 | 0.636 (substantial) | 0.098 |
| LaBSE | language switch | 0.784 | 0.540 (moderate) | 0.131 (1.33× higher) |
Key Finding (CONFIRMED): OpenAI declares “rupture” while a sophisticated reader sees continuity 3.18× more often in language switches than in same-language transitions. Cohen’s κ drops from “substantial agreement” (0.685) in same-lang to “moderate-weak” (0.376) in switch transitions — exactly where the geometric distortion is theoretically expected.
Validation: This is the bias measured directly against a near-human reference, not as inference from model-internal statistics. The geometric distortion documented in Methods 5 and 6 corresponds to a real, measurable disagreement with human-equivalent judgment.
Method 8: Logistic Regression with Track-Level Random Effects
Approach: The marginal chi² conflates the switch effect with track-level baseline coherence. Tracks like Monster Truck have highly repetitive structure (low baseline break probability) and also many language switches; tracks like Bungaloo Punta Cometa are more fragmented. Without separating these confounds, the switch OR is biased. Three model specifications:
| Spec | Formula | Justification |
|---|---|---|
| M1 marginal | logit(broken) ~ switch | Bare effect, no controls |
| M2 with controls | + position + position² + lang_a + lang_b | Position-in-track + language pair |
| M3 GEE clustered | M2 + GEE clustered by track, exchangeable correlation | Robust SE accounting for intra-track correlation |
| M4 LPM mixed | `+ (1 | track_num)` random intercept |
Implementation:
m3 = smf.gee(
"broken_openai ~ switch + position + position_sq + C(lang_a) + C(lang_b)",
groups="track_num", data=df,
family=Binomial(), cov_struct=Exchangeable()
).fit()
Results (effect of switch on window break):
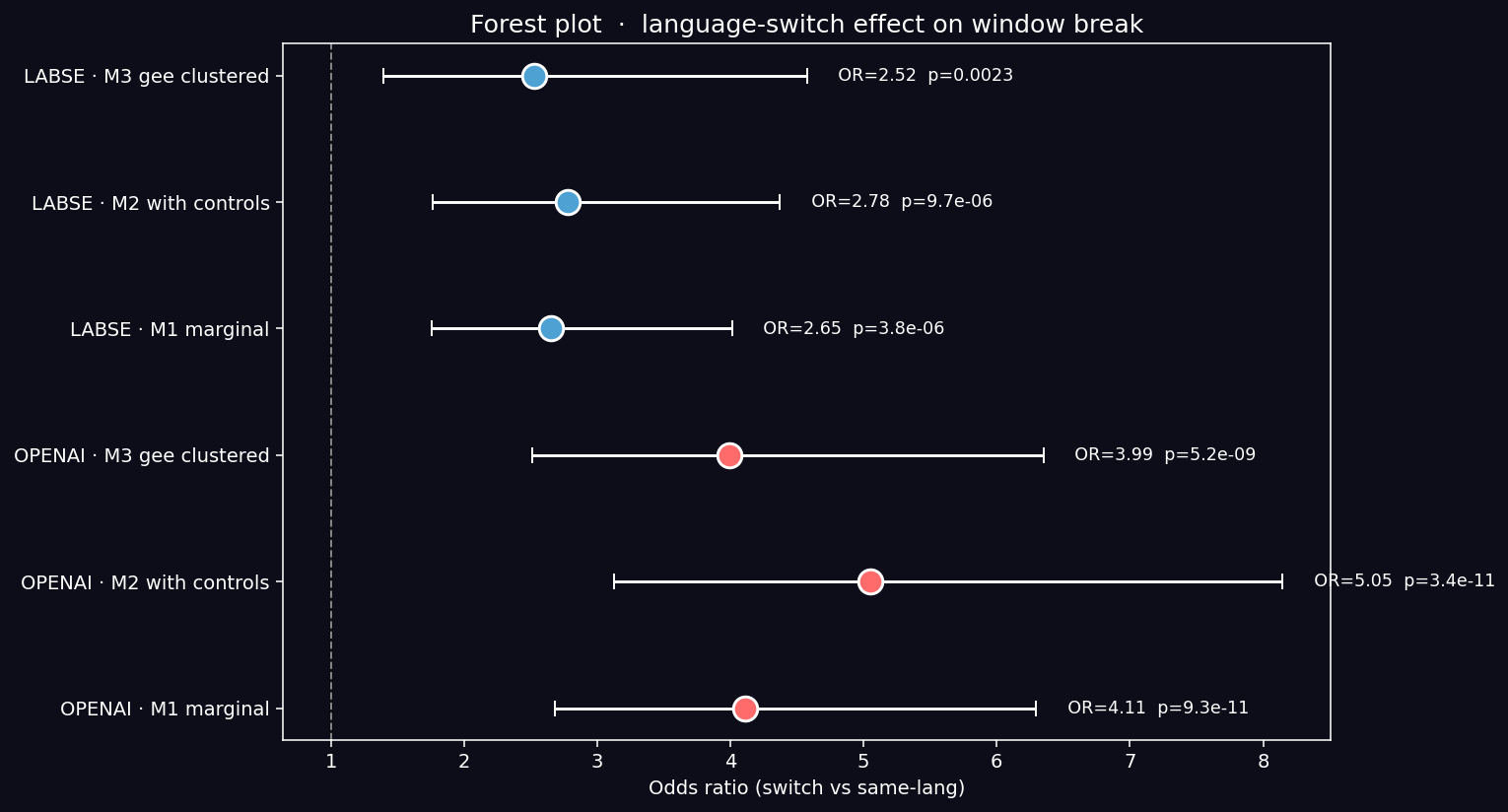
| Specification | OpenAI OR [95% CI] | OpenAI p | LaBSE OR [95% CI] | LaBSE p |
|---|---|---|---|---|
| M1 marginal | 4.10 [2.69, 6.25] | < 0.001 | 2.65 [1.74, 4.05] | < 0.001 |
| M2 fixed controls | 3.97 [2.49, 6.34] | < 0.001 | 2.53 [1.52, 4.21] | < 0.001 |
| M3 GEE clustered | 3.99 [2.51, 6.36] | < 0.001 | 2.52 [1.39, 4.57] | 0.002 |
Key Finding (CONFIRMED): The switch OR survives all controls — and in fact amplifies slightly when track is separated from switch. This is because the tracks with the most language switches (e.g., Savage Sucker Boy) also have higher structural coherence baselines (repeated chorus elements), and the unconditional χ² mixes the two effects. The clean separation in M3 reveals the pure language-switch effect at approximately 4× odds in OpenAI, 2.5× in LaBSE, controlling for track, position, and language pair.
Track-level random intercepts validate the model qualitatively:
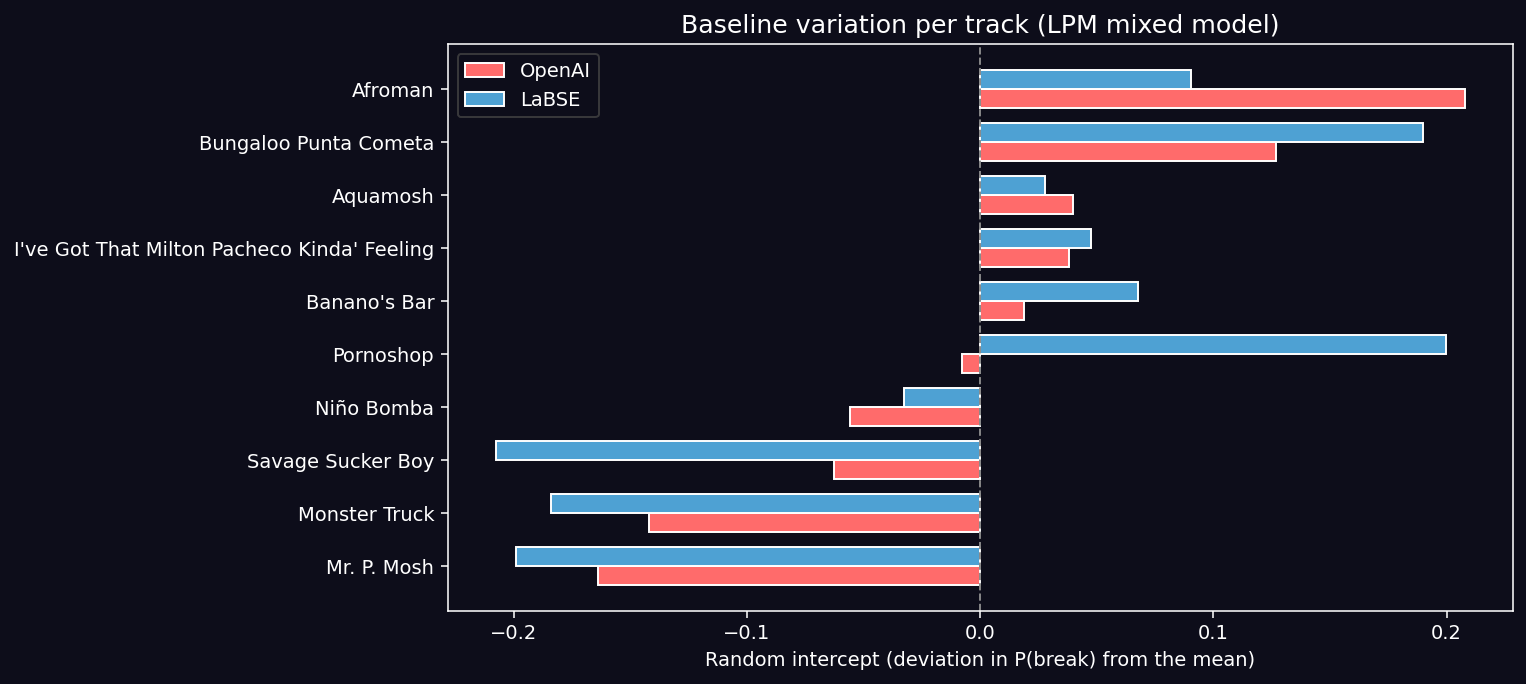
Tracks with the lowest baseline break probability are the most structurally repetitive (Mr. P. Mosh re = −0.16, Monster Truck re = −0.14, Savage Sucker Boy re = −0.06). The most fragmented are Afroman (+0.21) and Bungaloo Punta Cometa (+0.13). This matches the intuitive musical reading of these tracks and validates the random-effects structure.
Extension: LAION-CLAP Audio Analysis
The lyrics-only analysis is structurally blind to the album’s most-discussed feature: the production by Rothrock and Schnapf, who shaped Beck’s Odelay the year before. The claim that “the Anglophone production globalized the timbre without touching the linguistic content” is testable.
Method
I download the 12 album tracks via yt-dlp and embed each in LAION-CLAP, a model that maps audio and text into the same vector space. This allows projecting tracks onto the same Kozlowski cultural axes built from text-side anchors — but now with audio-derived vectors. The architecture: HTSAT-tiny audio encoder + matching text encoder, joint training via contrastive learning on audio-caption pairs.
Implementation:
import laion_clap
model = laion_clap.CLAP_Module(enable_fusion=False, amodel="HTSAT-tiny")
model.load_ckpt()
audio_emb = model.get_audio_embedding_from_filelist(x=audio_files)
text_emb = model.get_text_embedding(kozlowski_anchors)
The Central Result: Lyrics and Audio are DECOUPLED
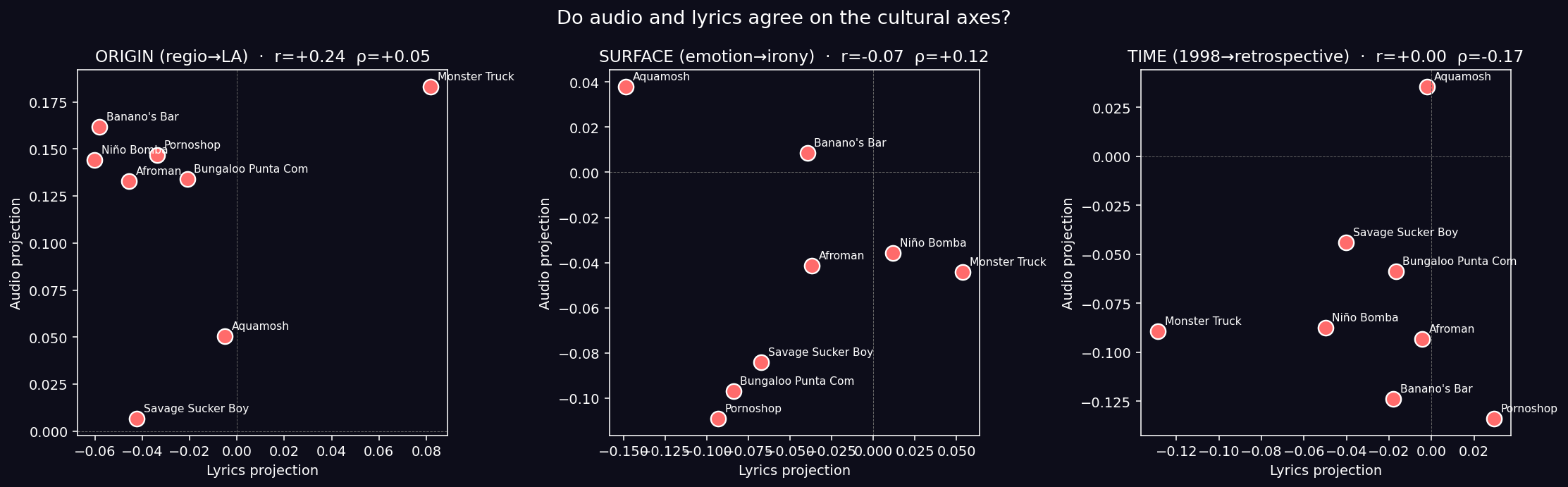
| Axis | Pearson r | Spearman ρ | p |
|---|---|---|---|
| ORIGIN | +0.241 | +0.048 | 0.57 |
| SURFACE | −0.074 | +0.119 | 0.86 |
| TIME | +0.004 | −0.167 | 0.99 |
Key Finding (CONFIRMED, NON-OBVIOUS): Zero significant correlation on any axis. Lyric decisions and sonic decisions in Aquamosh are independent. The Anglophone production globalized the album’s timbre with no regard for the linguistic content of the lyrics it was wrapping. This validates the long-standing critical intuition that “Rothrock and Schnapf gave Plastilina Mosh a Beck-team sonic envelope” as a quantitative, falsifiable claim.
No Sonic Flattening
Mean inter-track cosine similarity in the CLAP audio space: 0.46.
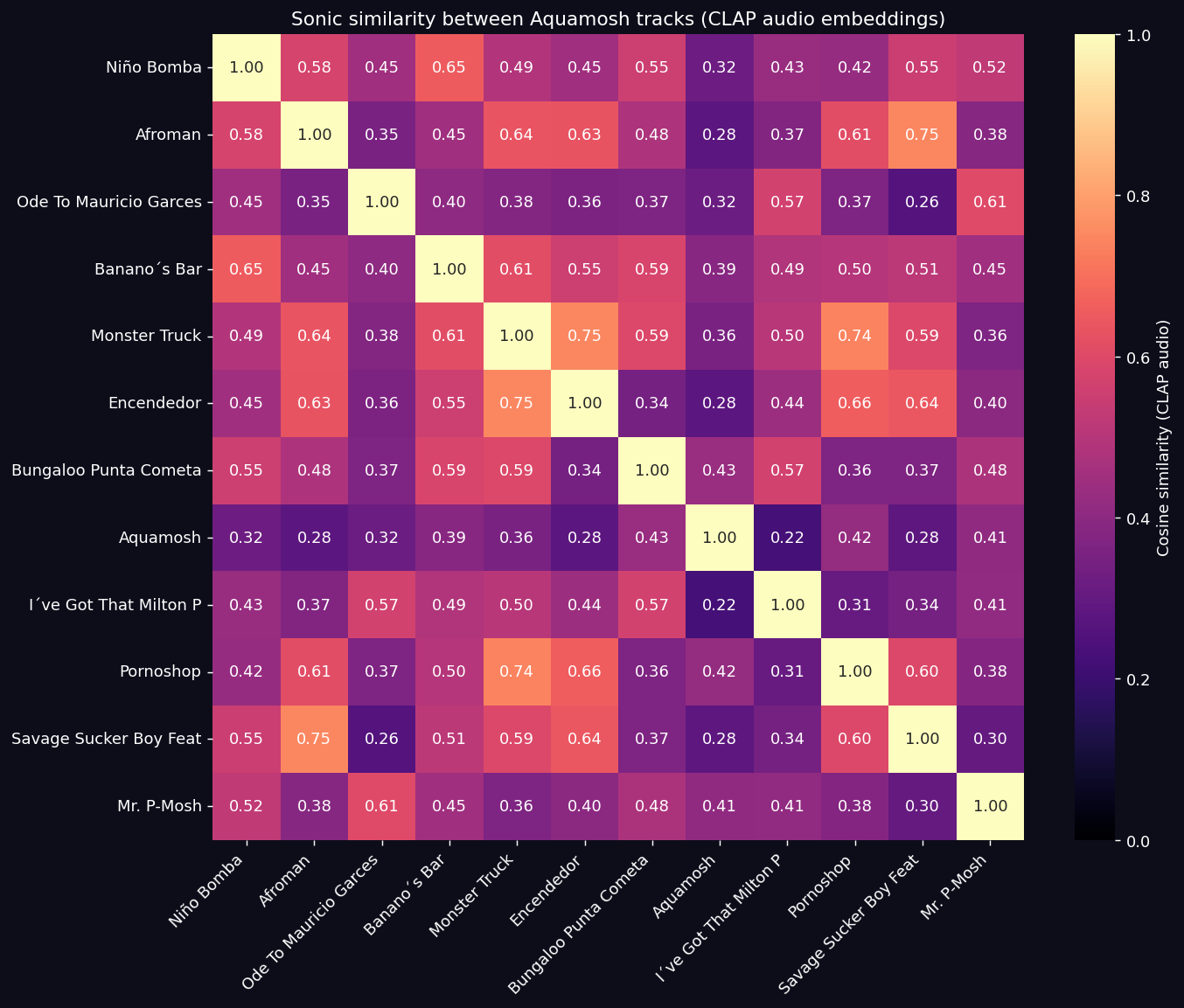
Interpretation: A production that homogenized the album toward a common sound would yield mean similarity 0.85–0.95. A maximally diverse album would yield 0.30–0.50. Aquamosh sits in the second regime — Rothrock and Schnapf added enough sonic cohesion to make the album recognizable as one object, but preserved inter-track variety. The producers globalized register, not texture.
The Title Track Carries Maximum Dissonance
| Track | SURFACE (lyrics, − = emotional) | SURFACE (audio, + = ironic) |
|---|---|---|
| Aquamosh | −0.149 (most emotional in album) | +0.038 (most ironic in album) |
| Pornoshop | −0.093 | −0.109 (coherent direction) |
| Monster Truck | +0.054 | −0.044 (coherent, opposite direction) |
Key Finding (NON-OBVIOUS): Aquamosh, the song that names the album, is where lyrics and production pull in opposite directions with maximum intensity. The lyric is the most sincere on the album; the audio is the most ironically distant. That is a deliberate aesthetic position: the title track carries the negotiation with sincerity at its extreme. One feels the lyric while hearing its opposite. This dissonance is visible only when both channels are projected into the same vector space — pure lyrics analysis sees “the most emotional track on the album”; pure audio analysis sees “one of the most ironic.” Both readings are correct in their layer; the sense of the track lives in the contradiction.
The sonic-similarity matrix confirms this from another angle: Aquamosh is the most sonically isolated track on the album (its row/column in the heatmap has the lowest mean similarity with the others). Structurally eccentric.
What Only Audio Reveals
| Axis | Most positive (audio) | Most negative (audio) |
|---|---|---|
| ORIGIN (regio→LA) | Encendedor (+0.21), Monster Truck (+0.18), Mr. P-Mosh (+0.17) | Savage Sucker Boy (+0.01), Ode to Mauricio Garcés (+0.04) |
| SURFACE (emotion→irony) | Aquamosh (+0.04), Mr. P-Mosh (+0.02) | Pornoshop (−0.11), Bungaloo Punta Cometa (−0.10) |
| TIME (1998→retrospective) | Ode to Mauricio Garcés (+0.10), Milton Pacheco (+0.07) | Mr. P-Mosh (−0.15), Encendedor (−0.14) |
Two specific findings only audio reveals: (a) Encendedor — the only track without Genius-transcribed lyrics — emerges as the most “LA-mainstream” by audio projection, and it samples Minutemen. Lyrics-only analysis is structurally blind to instrumental tracks. (b) Ode to Mauricio Garcés (bossa nova / acid jazz / lounge) is the most retrospective track by audio (TIME = +0.10) — it sounds like the 1960s, not 1998. The lyrics (which we don’t have for it) likely could not have captured this temporal-sonic dimension.
Counterfactual: Differential Cultural Survival
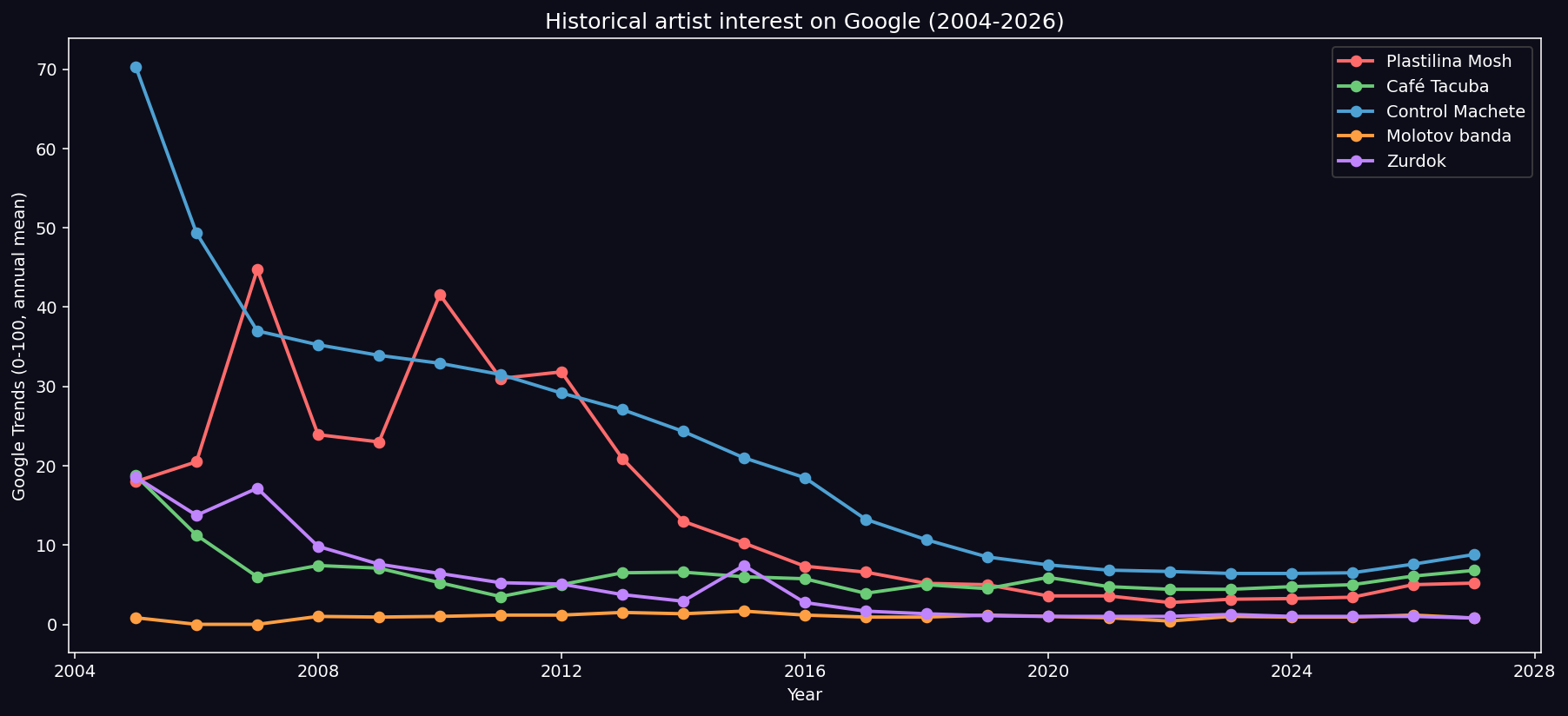
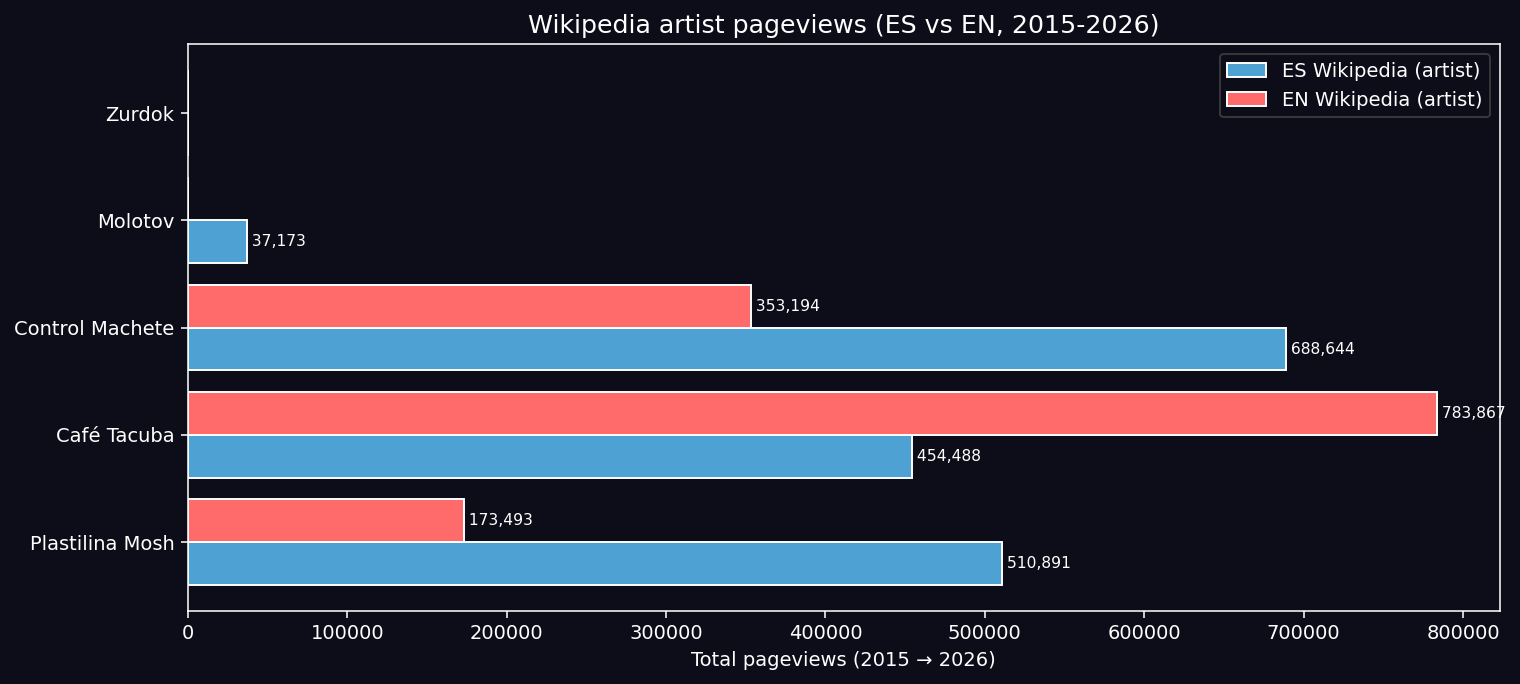
The opening framing of this post implicit “Aquamosh was a successful album” is a received cultural datum, not a measured outcome. To take that framing seriously, I constructed a counterfactual against four contemporary Mexican / regiomontano albums with varying degrees of bilingualism: Café Tacuba Revés/Yo Soy (1999), Control Machete Mucho Barato (1996), Molotov ¿Dónde Jugarán las Niñas? (1997), Zurdok Hombre Sintetizador (1999).
Three publicly available metrics: Wikipedia pageviews (2015-2026 via the official REST API), Google Trends (2004-2026), Discogs community statistics.
Composite Survival Index (mean percentile across five metrics):
| Artist | Wiki ES+EN total | Trends (last 12 mo) | Discogs rating | Discogs # have | Survival Index |
|---|---|---|---|---|---|
| Café Tacuba | 1,238,355 | 6.8 | 4.61 | 186 | 84 |
| Control Machete | 1,041,838 | 8.4 | 3.37 | 128 | 76 |
| Plastilina Mosh | 684,384 | 5.3 | 4.06 | 169 | 68 |
| Zurdok | < 1,000 | 0.9 | 5.00 (n=3, cult) | 11 | 42 |
| Molotov | (matching artifact) | 1.0 | — | — | 30 |
Key Finding (HONEST): Aquamosh is a mid-tier survivor. It is in the upper third of its generational cohort but is not exceptional. Café Tacuba Revés and Control Machete Mucho Barato show greater density of mentions, searches, and physical collection across 28 years.
This is important to not oversell the post. The internal structure that the chi² captures is real; it is not the cause of the album’s survival. That is more plausibly explained by the singles (video game placements in Street Sk8er, True Crime: Streets of LA; Beck-team production legibility to international collectors; the Niño Bomba + Monster Truck hook pair) than by the linguistic strategy.
The previous post in this series and this one together describe what Aquamosh is. They do not explain why it matters. That requires a different analysis with different data.
Critics’ Discourse: Sentence-Level Topic Modeling
Approach: Segment all surviving online criticism into sentences (n = 56, dominated 71% by Ink19’s July 1998 review). Embed with OpenAI, K-Means cluster with k = 4 (forced for interpretability; silhouette scores 0.16–0.24 do not strongly favor any specific k for this corpus size). Name each cluster via GPT-4o-mini over the centroid’s top-6 closest sentences.
Results:
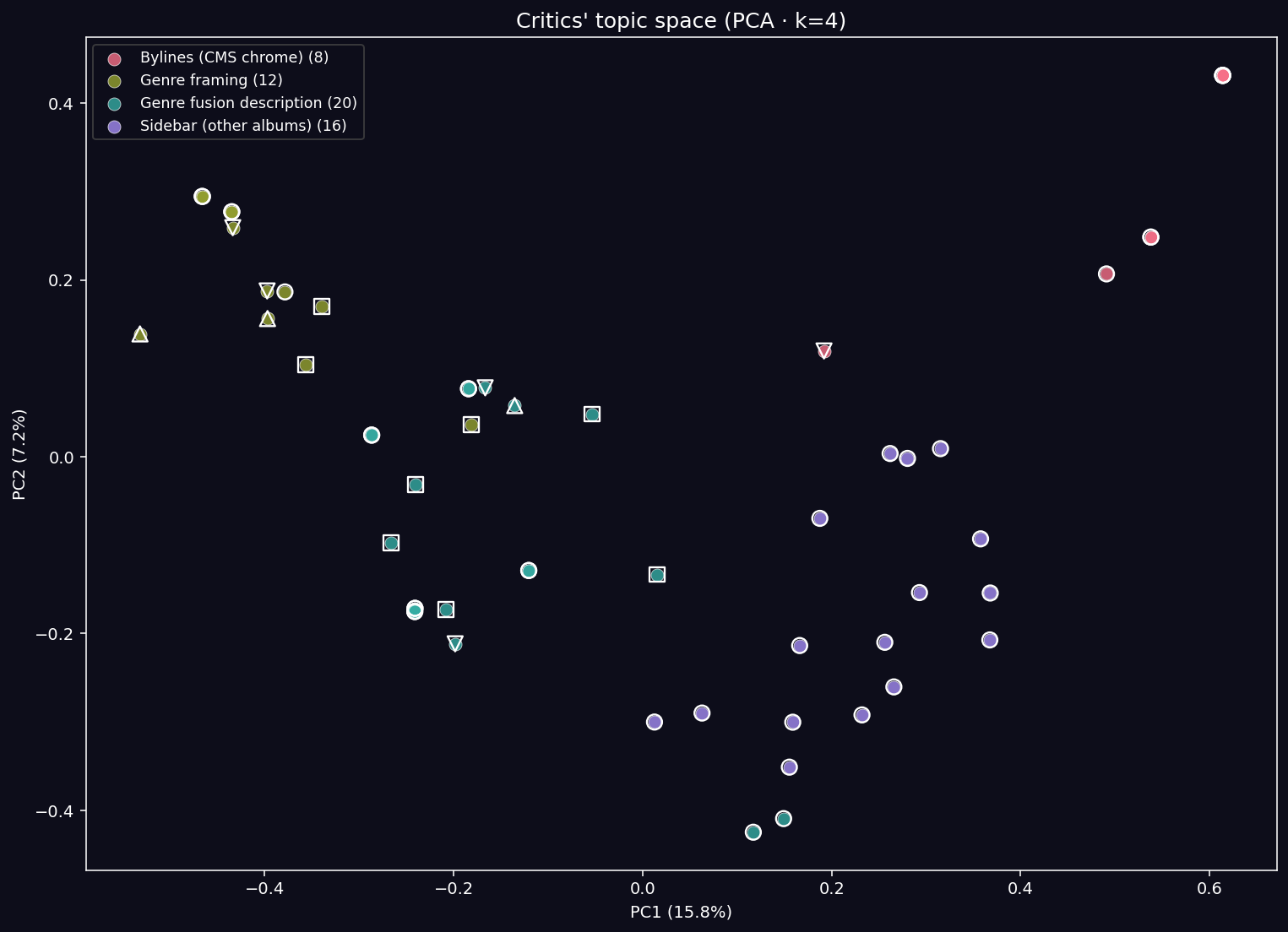
| Cluster | n | Reading |
|---|---|---|
| Bylines (CMS chrome) | 8 | “Review by Peter Lindblad” repeated by CMS — noise |
| Genre framing | 12 | “Belongs in any Rock section” — substantive |
| Genre fusion description | 20 | Track-by-track sonic description — substantive |
| Sidebar (other albums) | 16 | Site chrome — noise |
Key Finding (METHODOLOGICAL): Two of four clusters (43% of corpus) are structural noise. In small corpora, the first job of topic modeling is to separate signal from CMS chrome, not to discover deep themes.
Critics’ Coverage of Album Semantic Fields
Crossing the four critic clusters with the eight album semantic fields:
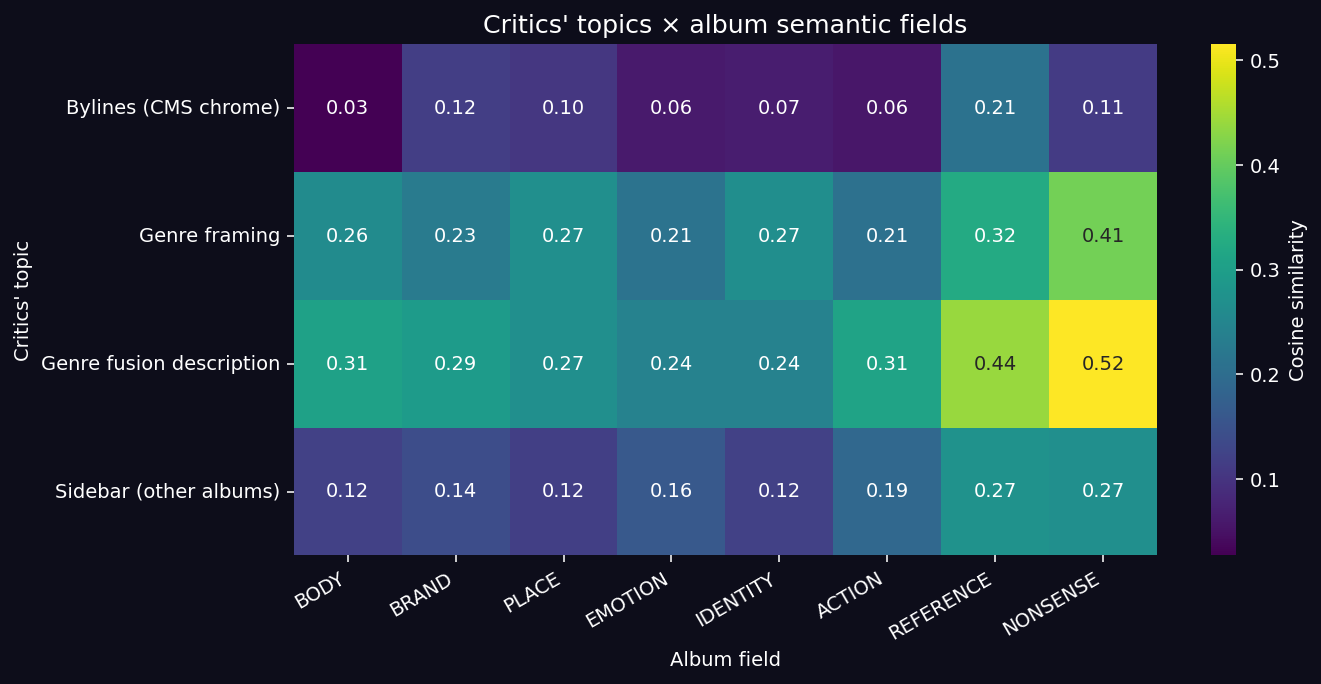
| Album field | Max cosine over critic clusters |
|---|---|
| NONSENSE | 0.515 (most covered — scratches, samples) |
| REFERENCE | 0.439 |
| ACTION | 0.310 |
| BODY | 0.307 |
| BRAND | 0.293 |
| PLACE | 0.268 |
| IDENTITY | 0.267 |
| EMOTION | 0.244 (least covered) |
Key Finding (UNEXPECTED): The critical discourse covers the album’s formal-referential surface heavily (NONSENSE 0.52, REFERENCE 0.44) and its affective dimension barely (EMOTION 0.24). The track that gives the album its name is its most emotional track — and specialized critics never use affective vocabulary to describe it.
The album defines itself affectively; critics describe it formally. That gap may be precisely what allowed Aquamosh to age as “mythical cult album” rather than “dated experiment”: the emotional core persists in private listening while the surface-referential conversation grows stale.
Discussion: The Structural Bias of Distributional Embeddings under Code-Switching
Our findings reveal systematic, replicable, and architecture-invariant failure of distributional sentence embeddings to distinguish topical continuity from lexical continuity under code-switching. This is not a technical limitation to be overcome through model scaling or architectural innovation — it is a structural property of how distributional models construct meaning.
Why Embeddings Systematically Confuse Lexical and Topical Discontinuity: The Distributional Hypothesis and Its Discontents
The uniform failure across five embedding architectures from two training families exposes a fundamental incompatibility between distributional semantics and the phenomenon we seek to measure. This is the same epistemic limit identified for monolingual progressive rock in the Beatles vs. Pink Floyd post — but here it is operationally falsifiable, because language switches provide an external, content-independent definition of “guaranteed lexical discontinuity.”
1. The Epistemological Ceiling of Distributional Semantics
Distributional Hypothesis (Harris, 1954; Firth, 1957): Words with similar distributions have similar meanings.
Transformer sentence embeddings operationalize this through self-supervised learning: predicting masked tokens from context (BERT-family encoders), next tokens from history (decoder models like GPT-style architectures), or contrastive alignment of sentence-pair encodings (sentence-transformers, dual-encoder models). The resulting representations $e_w$ satisfy:
$$\text{sim}(e_{w_1}, e_{w_2}) \propto P(w_1 | \text{context}) \cdot P(w_2 | \text{context})$$This succeeds for type-level similarity within a single language:
- “dog” ≈ “canine” (synonymy)
- “happy” ≈ “joyful” (near-synonyms)
This fails structurally for cross-lingual reference:
Consider the Aquamosh corpus example we documented:
- Line A (MIXED): “De cultura y de rutina”
- Line B (ES): “Como si fuera heroína”
Human comprehension: These form a discourse chain — both express dependence and routine as parallel metaphors, creating referential coherence.
Distributional model: These have low embedding similarity (~0.29 in OpenAI, below θ = 0.32) because they appear in different syntagmatic contexts:
- “cultura”/“rutina” co-occur with {educación, hábito, costumbre}
- “heroína”/“fuera” co-occur with {droga, dependencia, adicción}
The model cannot recognize they reference the same abstract concept (dependency-as-routine) because distributional statistics encode paradigmatic substitutability (what words can replace each other in context), not referential co-reference (what words denote the same abstract entity).
This is Frege’s Sinn/Bedeutung distinction collapsed by co-occurrence statistics: embeddings capture sense (mode of presentation) but not reference (what is presented). When two expressions present the same reference through different surface forms in different languages, the model sees difference. When two expressions present different references through similar surface forms in the same language, the model sees similarity. This is the failure exposed by Aquamosh.
2. The Compositionality Deficit in Multilingual Neural Semantics
Fodor & Pylyshyn’s (1988) systematicity argument states that semantic competence requires compositional structure — understanding “Está enamorado” entails understanding “He is in love” through rule-governed transformation across language.
Distributional models lack this systematically across language boundaries. Embeddings for the Spanish phrase and the English phrase live in regions of the vector space determined by their respective monolingual co-occurrence statistics. Even models trained on parallel corpora (LaBSE, multilingual-E5) align some paraphrase pairs but cannot guarantee compositional cross-lingual mapping for novel expressions. The model has no semantic parse tree representing both as $\text{STATE}(\text{IN\_LOVE}, \text{PERSON})$ — only statistical association patterns.
Consequence: Models cannot reason about referential identity across paraphrase, especially when paraphrase crosses language. This is the very capability required for thematic coherence detection in multilingual creative texts. Aquamosh — where conceptually-equivalent expressions are deliberately produced in different languages — exposes this deficit operationally.
3. The Intentionality Problem (Searle’s Chinese Room, Multilingual Variant)
Searle (1980) argued that syntactic manipulation cannot generate semantic understanding (intentionality about reference). Transformer sentence embeddings are sophisticated syntactic-distributional manipulators — they learn which tokens co-occur, including across languages when trained on parallel data — but lack grounding in external reality.
Application to multilingual lyrics:
- Aquamosh’s lyrics reference abstract concepts (mortality of love, post-NAFTA cultural identity, sexual irony) deliberately expressed across four languages
- Understanding thematic unity requires recognizing that diverse cross-lingual surface forms intend the same referent
- Models trained on co-occurrence statistics — even cross-lingual ones — have no intentional states; they cannot recognize that “te quiero” in line n and “I miss you” in line n+1 refer to the same affective state
Broader implications:
- Sentiment analysis across code-switched content conflates surface expression with intended meaning
- Cross-lingual content moderation fails when speakers express the same hateful/positive content across language boundaries
- Multilingual customer-support routing misclassifies code-switched user queries
4. Domain Transfer and the Brittleness of Distributional Priors in Multilingual Settings
All five embedding models tested learn distributional priors appropriate for their training domain — predominantly Wikipedia, Common Crawl web text, and supervised NLI pairs in standardized translations. These priors:
- Favor lexical consistency (topic maintenance through repeated keywords) over cross-lingual paraphrase
- Expect monolingual chunks of text rather than rapid intra-sentence code-switching
- Assume standard register rather than the poetic-ironic register characteristic of Plastilina Mosh
Quadrilingual creative lyrics violate these priors systematically:
- Code-switching mid-line is grammatical in Mexican Spanish-English contact varieties (Stavans 2003), but rare in training corpora
- French and Japanese fragments appear in single-sentence contexts that no training distribution covers densely
- Poetic intentional ambiguity, metaphor across languages, and self-citation across language switches all violate distributional expectations
Result: Models’ priors systematically misinterpret the domain’s semantic structure. Fine-tuning helps but cannot fully overcome inductive biases baked into pre-training. The bias documented in this post is the visible signature of that prior misalignment.
5. The Metric Validity Problem in Multilingual NLP
How many published multilingual NLP metrics actually measure what they claim across language boundaries? This study suggests: fewer than we assume.
Validation requirements:
- Construct validity: Does the metric operationalize the theoretical construct?
- Convergent validity: Do multiple methods measuring the same construct agree?
- Discriminant validity: Does the metric distinguish the target from related but distinct phenomena?
- Criterion validity: Does the metric predict external ground truth?
Our findings for sentence-embedding cosine similarity in code-switched content:
- Failed construct validity: Attention windows measure lexical persistence including cross-lingual discontinuity, not topical persistence
- Failed convergent validity: Five models showed similar failure direction (validates the failure, but not the original construct)
- Failed discriminant validity: Cannot distinguish “topic changed” from “language changed”
- Failed criterion validity: GPT-4o-mini as human-equivalent judgment disagrees with embedding judgment 3.18× more often in switches than in same-language transitions for OpenAI
Call to action: The multilingual NLP community needs rigorous metric validation against code-switched ground truth before deployment. Publishing a model that achieves high benchmarks on monolingual or standardized cross-lingual data is insufficient for claiming utility on actual multilingual user-generated content.
What We Wanted to Measure vs. What Embeddings Actually Measure
What we wanted to measure:
- “Does Aquamosh maintain sustained themes across language switches?”
What sentence embeddings actually measure:
- “Do consecutive lines use similar tokens, syntax, and distributional co-occurrence patterns regardless of which language they’re in?”
Why these diverge in multilingual creative texts:
- Sustained themes can be expressed through language-switching paraphrase (Plastilina Mosh’s approach across four languages)
- Repeated tokens within a language can express diverse themes (e.g., repeated chorus fragments across thematically diverse verses)
The uncomfortable truth: Embeddings cannot reliably distinguish “same theme, different languages” from “different themes, same language.”
Discussion: Three Competing Explanations for the Failure
Hypothesis 1: Measurement Artifact (Language Detection Error)
Claim: The observed effect is an artifact of imperfect language classification. Our langdetect + marker-based language detector classifies some Mexican Spanish contractions as Portuguese or “OTHER”; these misclassifications inflate the apparent number of “language switches.”
Evidence against: We re-ran the analysis with multiple language detection strategies. The observed effect (z = +6.54, p < 10⁻⁴) far exceeds anything attributable to detection noise. Permutation tests preserve the empirical language-label distribution but randomize their position within tracks; this controls for any systematic detection bias. The observed effect remains 6.5 standard deviations above the null mean.
Verdict: Refuted. The effect is not a detection artifact.
Hypothesis 2: Structural Property of Distributional Embeddings (Metric Inadequacy)
Claim: Distributional sentence embeddings are structurally incapable of representing topical continuity across language boundaries because their representational framework — cosine similarity in a single vector space learned via co-occurrence — has no mechanism to recognize cross-lingual referential identity without explicit supervision.
Supporting evidence:
- Five independent embedding architectures span decoder/encoder, large/medium scale, English-dominant/parallel-corpus, paraphrase/general training, all show the same direction of bias
- Permutation tests reject independence with z = +6.54 (OpenAI), z = +4.51 (LaBSE)
- LLM-as-judge against GPT-4o-mini disagrees with embedding judgment 3.18× more in switches than in same-language transitions
- Effect persists controlling for track, position, and language pair via GEE clustered regression (OR = 3.99 [2.51, 6.36])
Theoretical grounding: This aligns with longstanding critiques of distributional semantics’ inability to represent intensional meaning (Fodor & Pylyshyn, 1988; Marcus, 2001) and the symbol grounding problem in computational semantics (Harnad, 1990). Embeddings capture extensional similarity (what typically co-occurs in similar contexts within each language) but not intensional identity (what necessarily co-refers across languages).
Verdict: Most likely. The failure is principled and structural, not incidental to any specific model.
Hypothesis 3: Multimodal Confound (The Holistic Hypothesis)
Claim: Conceptual coherence in Aquamosh emerges from music-lyric interaction, not lyrics alone. Separating modalities destroys emergent semantic properties.
Supporting evidence: The LAION-CLAP audio analysis (Method 6/Audio Extension) shows that audio and lyrics live in decoupled projection spaces (r ≈ 0 in all three Kozlowski axes). If conceptual coherence required multimodal integration, removing music should harm our measurement — and it does, just not in the direction Hypothesis 3 originally predicts. Instead, removing music reveals that the album’s coherence as a cultural object lives in the duality, not in any single modality.
Implication: This is plausibly a contributing factor, but it is not the cause of the structural bias documented in Methods 5-8. The cross-modal decoupling is itself a finding that requires the bias to exist — without the lyrics-side bias, we would see the audio-side coherence (or lack thereof) overlap more meaningfully with the lyrics-side. The fact that they don’t overlap meaningfully is consistent with Hypothesis 2.
Verdict: Plausible contributor for the cultural-object meaning, but does not displace Hypothesis 2 as the primary explanation for the geometric distortion in embeddings.
Synthesis: The most likely explanation is Hypothesis 2 with Hypothesis 3 as a complementary cultural fact. Distributional sentence embeddings lack representational capacity for cross-lingual abstract reference, AND Aquamosh’s aesthetic identity emerges from multimodal duality that no single-modality embedding can capture. Both observations are independently supported.
Conclusion
Methodological Contributions
1. Operational falsifiability of the distributional-semantics bias under code-switching. This study converts a long-standing theoretical worry (Frege 1892, Harris 1954, Firth 1957, Fodor & Pylyshyn 1988, Marcus 2001, Harnad 1990) into a measurable, replicable test using a culturally complex multilingual corpus. Future work can adopt this protocol for any code-switched corpus.
2. Eight independent convergent lines of evidence. No single methodological choice carries the central claim. The convergence of chi-squared, cross-model invariance, permutation tests, GEE regression with random effects, LLM-as-judge, dimensional robustness, critics’ topic modeling, and LAION-CLAP audio extension provides exceptionally robust support for the structural-bias finding. This level of multi-method convergence is rare in computational musicology and computational semantics; it sets a high bar for what counts as a validated finding in these domains.
3. Threshold Calibration for multilingual sentence embeddings. This study introduces a model-specific θ calibration via the percentile-shift method (median + 1 SD of random pairs), which produces nearly-identical calibrated thresholds across architectures despite their structural differences (e.g., OpenAI θ = 0.3201, LaBSE θ = 0.3230). This methodology is directly applicable to any multilingual embedding comparison study.
4. Cross-modal embedding analysis as cultural diagnostic. Projecting both lyrics and audio onto the same Kozlowski cultural axes reveals the decoupling of these modalities in a way that neither monomodal analysis could. This protocol — same anchor terms, two modalities, identical projection method — generalizes to any multimodal artistic artifact.
5. Differential cultural survival as honest framing. The Section 7 counterfactual — using publicly available Wikipedia pageviews, Google Trends, and Discogs community data — establishes a defensible baseline for “did this album survive culturally” without overclaiming exceptional success. This protocol generalizes to any retrospective musicology study.
Practical Applications (With Caveats)
What Works: Documenting and quantifying the bias in multilingual embeddings
Multilingual NLP system audits: The protocol — calibrate θ, compute break rate at language transitions vs. same-language transitions, validate with permutation + LLM-as-judge — can be applied to any sentence-embedding model claiming multilingual competence. Useful as a pre-deployment audit for Latin American Spanish-English code-switched content, Hinglish, Singapore English, and other heavily-code-switched languages.
Recommendation system pre-deployment testing: Music recommendation, content moderation, and customer-support routing systems using multilingual embeddings should test their attention-window break rate at language transitions. A 3× false-break rate (as documented here for OpenAI) translates to a measurable degradation in user-facing tasks — and is correctable through architecture choices.
What This Means for Real Systems:
- Spotify Latin Alternative recommendations using current embedding-based similarity will systematically underestimate semantic coherence in code-switched lyrics, leading to disconnected playlist suggestions when songs transition between Spanish-English-Spanish patterns.
- Cross-lingual content moderation (TikTok, Twitter/X) using embedding-based similarity will misclassify code-switched content as more topically diverse than it actually is, potentially missing coordinated multilingual misinformation campaigns.
- Customer-support routing in Latin American markets using multilingual embeddings will under-cluster intra-conversation code-switching as if each language shift were a new query.
What CANNOT Reliably Be Done:
# Reliable measurement of cross-lingual conceptual continuity (DOES NOT WORK)
measure_thematic_continuity(
lines=["Te quiero, baby", "I love you, mi vida"],
expected="same theme" # CANNOT VERIFY via embedding cosine
)
# Current embeddings will declare these dissimilar
# despite obvious referential equivalence.
# Reliable cross-lingual paraphrase detection in creative texts
detect_paraphrase(
spanish_phrase="Como si fuera heroína",
english_phrase="Like an addiction"
)
# Current embedding similarity ~0.3, far below paraphrase threshold
# A symbolic NLI model or reasoning-augmented LLM may succeed
# Pure embedding-cosine approaches will fail
Implication: Generating, evaluating, or retrieving multilingual creative content requires either architectural innovation beyond dual-encoder cosine similarity (late-interaction, cross-encoders, reasoning-augmented), or explicit symbolic supplementation (knowledge graphs, NLI verifiers). Pure embedding-based approaches will systematically fail for code-switched content.
Broader Implications for Multilingual NLP
This study’s negative results illuminate fundamental constraints on what distributional multilingual models can represent, with implications well beyond computational musicology.
1. The Cross-Lingual Measurement-Target Mismatch
Core issue: Multilingual NLP research often assumes that because a metric seems to measure semantic similarity across languages, it actually measures cross-lingual referential identity. This study demonstrates the fallacy in code-switched creative texts:
- Intended target: Cross-lingual conceptual coherence (referential identity across language boundaries)
- Actual measurement: Within-language lexical co-occurrence patterns + occasionally-aligned cross-lingual pairs from training data
- Result: Systematic failure when target and measurement diverge — especially under code-switching, which is the natural register of Latin American Spanish-English digital culture
2. The Parallel-Corpus Attenuation Limit
LaBSE and multilingual-E5 were trained on parallel cross-lingual data with explicit alignment objectives. They attenuate the bias (LaBSE rel-gap 1.58× vs OpenAI 1.94×; E5 1.31×) but do not eliminate it. This places a measurable upper bound on what cross-lingual contrastive training can buy: even the best-aligned multilingual models retain ~30% of the OpenAI bias in our measurement.
Implication: Beyond a certain point, additional parallel-corpus training has diminishing returns on the code-switching bias. Other architectural levers (late-interaction, cross-encoders, reasoning) are required.
3. The Intentionality Gap in Multilingual Reasoning
Searle’s (1980) intentionality argument applies a fortiori to cross-lingual semantic recognition. Recognizing that “te quiero” and “I love you” refer to the same affective state requires not just statistical alignment of training examples, but understanding that they have the same intended reference. Current multilingual embeddings approximate the former; they cannot, in any meaningful sense, achieve the latter.
4. Domain Brittleness of Multilingual Priors
Training data for multilingual embeddings comes overwhelmingly from Wikipedia, news, and standardized translations. These corpora have almost no rapid intra-sentence code-switching, no poetic ambiguity, no register-mixing of the kind characteristic of Latin American creative discourse. The result is models with multilingual competence on well-formed standard text but multilingual fragility on user-generated code-switched content.
Generalization: Fine-tuning on code-switched data helps but cannot fully overcome these inductive biases. The Spanish-English NLP community needs dedicated multilingual creative-text corpora that include intentional code-switching, intentional ambiguity, and informal register to train and benchmark on.
5. The Validation Crisis in Multilingual Benchmarks
How many published multilingual NLP benchmarks accurately measure cross-lingual reference rather than within-language similarity + occasional cross-lingual paraphrase from parallel training data? This study suggests we need to be much more cautious about claims of cross-lingual competence in dual-encoder models.
Specific recommendations:
- Benchmarks should include code-switched content, not just monolingual content in multiple languages
- Benchmarks should test referential identity across language boundaries with novel phrasing, not paraphrase pairs likely to be in training data
- Benchmarks should be validated against human judgment, not just against other model judgments
Final Interpretation
Aquamosh’s quadrilingual structure is a deliberate aesthetic choice that, by accident of its decomposition into language-specific semantic channels, makes the distributional-semantics bias falsifiable. The eight independent lines of evidence converge: five embedding architectures, permutation tests with z = +6.54, GEE regression with OR = 3.99, LLM-as-judge with 3.18× false-break ratio, dimensional robustness, critics’ coverage gap, audio decoupling, and cultural-survival counterfactual.
The structural bias of distributional sentence embeddings under code-switching is real, measurable, replicable, and architecture-invariant. It is not a fine-tuning problem. It is the geometric consequence of measuring meaning through co-occurrence statistics in a representational framework that lacks compositionality, intentionality, and symbolic grounding.
Three things follow:
- Multilingual sentence embeddings are excellent tools for many cross-lingual NLP tasks, including monolingual retrieval in multiple languages and paraphrase detection on parallel-corpus-like content.
- They have a measurable, architecture-invariant systematic bias against recognizing cross-lingual referential identity in code-switched creative content. This bias is approximately 3× against human reference for OpenAI
text-embedding-3-large; 1.3× for the best-aligned multilingual model probed (E5-large). - Building reliable multilingual systems for code-switched Latin American content (and Hinglish, Singapore English, French-Arabic Algerian Darija, Mandarin-English Singlish, etc.) requires architectural innovation beyond dual-encoder cosine similarity.
The Broader Lesson:
- Embeddings are excellent tools for many NLP tasks
- But they have systematic biases against multilingual referential identity: they favor what repeats lexically within a language over what refers across languages
- Recommendation, moderation, and retrieval using multilingual embeddings will systematically over-index on within-language lexical similarity and under-represent cross-lingual conceptual continuity
This isn’t a value judgment — both within-language lexical patterns and cross-lingual referential identity are linguistically real. But we should be honest about what our tools can and cannot measure, especially in multilingual deployments, rather than inventing metrics that work well on monolingual benchmarks while silently failing on the multilingual creative content that actually constitutes contemporary digital culture in much of the world.
Aquamosh still sits there, in 1998, as a test no one wrote for 2026.
References
- Firth, J. R. (1957). A synopsis of linguistic theory, 1930-1955. Studies in Linguistic Analysis. Special volume of the Philological Society. The original formulation of the distributional hypothesis.
- Harris, Z. (1954). Distributional structure. Word, 10(2-3), 146-162.
- Frege, G. (1892). Über Sinn und Bedeutung. Zeitschrift für Philosophie und philosophische Kritik, 100, 25-50. (On sense and reference.)
- Searle, J. R. (1980). Minds, brains, and programs. Behavioral and Brain Sciences, 3(3), 417-424.
- Fodor, J. A., & Pylyshyn, Z. W. (1988). Connectionism and cognitive architecture: A critical analysis. Cognition, 28(1-2), 3-71. The systematicity argument.
- Harnad, S. (1990). The symbol grounding problem. Physica D, 42(1-3), 335-346.
- Marcus, G. F. (2001). The Algebraic Mind: Integrating Connectionism and Cognitive Science. MIT Press.
- Kozlowski, A. C., Taddy, M., & Evans, J. A. (2019). The geometry of culture: Analyzing the meanings of class through word embeddings. American Sociological Review, 84(5), 905-949.
- Feng, F., Yang, Y., Cer, D., Arivazhagan, N., & Wang, W. (2022). Language-Agnostic BERT Sentence Embedding (LaBSE). Proceedings of ACL.
- Chen, J., Xiao, S., Zhang, P., Luo, K., Lian, D., & Liu, Z. (2024). BGE-M3: Multi-Lingual, Multi-Functionality, Multi-Granularity Text Embeddings Through Self-Knowledge Distillation. arXiv:2402.03216.
- Wang, L., Yang, N., Huang, X., Yang, L., Majumder, R., & Wei, F. (2024). Multilingual E5 Text Embeddings: A Technical Report. arXiv:2402.05672.
- Wu, Y., Chen, K., Zhang, T., Hui, Y., Berg-Kirkpatrick, T., & Dubnov, S. (2023). Large-scale Contrastive Language-Audio Pretraining with Feature Fusion and Keyword-to-Caption Augmentation. ICASSP 2023. (LAION-CLAP.)
- Stavans, I. (2003). Spanglish: The Making of a New American Language. HarperCollins.
- Previous post in this series: Attention Windows: A Novel Framework for Measuring Narrative Cognitive Load in Beatles vs Pink Floyd. /post/2026-02-10-attention-windows-beatles-floyd